C++的主要特点是: 抽象和封装,继承和派生,多态性。而这些特性主要是通过类实现的。所以有必要详尽总结一下类的特性。
在编译阶段出现错误优于在运行阶段出现的错误;应该把诸多细节集中起来处理,便于程序的维护。
类总体思想
采用过程性编程方法时,首先考虑要遵循的步骤,然后考虑如何表示这些数据(并不需要程序一直运行,用户可能希望能够将数据存储 在一个文件中,然后从这个文件中读取数据)。而采用 OOP 方法时,首先从用户的角度考虑对象——描述对象所需的数据以及描述 用户与数据交互所需的操作。完成对接口的描述后,需要确定如何实现接口和数据存储。
面向对象编程强调的是程序如何表示数据,使用 OOP 方法解决编程问题的第一步是根据它与程序之间的接口来描述数据,从而指定如何 使用数据。
1
C++ 的目标之一是让使用类对象就像使用标准(内建)类型一样。
说到类型,那如何确定类型?借鉴 C 语言的思想可知有一下两点:
- 根据数据的外观(在内存中如何存储)来考虑数据类型。
- 根据要对它执行的操作来定义数据类型。
可见指定基本类型完成了三项工作:
- 决定数据对象需要的内存数量;
- 决定如何解释内存中的位(都是二进制,但解读不一样)
- 决定可使用数据对象执行的操作或方法。
对于内置类型来说,有关操作的信息被内置到编译器中。但在 C++ 中定义用户类型时,必须自己提供这些信息。付出这些劳动来获得 根据实际需要定制新数据类型的强大功能和灵活性。为了达到和内部类型一样的使用方法同时兼顾 OOP 思想的限制,必须提出一些 新的关键字和新的约定,方能保持 OOP 的同时被编译器识别。
1
类与 C/C++ 内置类型的相似性如下表:
| 内置类型 | 类 | |
| 声明 | int n; | className name; |
| 定义 | int m; int n=1; | 默认构造函数(或默认值初始化函数)和重载构造函数 |
| 赋值 | m = n; | 默认赋值函数和重载赋值函数 |
| 运算 | m += n; | 重载运算符 |
| 函数 | 全局作用域 | 类作用域 |
| 访问方式 | 默认公有成员 | 默认私有数据成员 |
| 信息隐藏 | 局部变量 | 类私有数据成员 |
| 代码块重用 | 函数 | 类(包括成员函数) |
| 重用方式 | 库函数调用 | 类库、继承、虚函数、接口、模板等 |
| 数据保护方式 | 作用域和 const | 访问控制符,类作用域,友元,继承等 |
| 接口 | 函数参数和返回值 | 另外加成员函数本身等 |
| 内存管理 | 系统自动释放 | 析构函数 |
| 不同类型处理方式 | typedef 和函数重载 | 类模板,成员函数重载 |
| 指针类型 | 完全匹配 | 基类可以指向派生类 |
| 类型转换 | 隐性或强制 | 转换函数或单参数构造函数 |
| 函数调用 | 直接调用 | 使用对象调用函数 |
| 类型指示 | this指针自动引入函数 | |
| 函数声明位置 | 调用者之前 | 类内部 |
| 函数定义 | 无需限定符 | 使用类限定符 |
| 封装 | 头文件声明和函数实现分开 | 类声明和成员函数定义分开 |
| 多态 | 函数重载 | 基类和派生类、不同派生类之间行为不同 |
从上表的确可以看出,类不断地通过封装、重载、多态等更好地向内置类型靠拢。使得类的使用与内置类型尽量的靠近。这给我们的启示 是:首先按照思维惯性像使用内置类型一样使用类,然后不同的地方或效率问题再重新学习。从而最大限度地利用已有的技能。
后面将从设计思想上讲解,类是如何做到使用习惯和内置类型尽量靠近的。
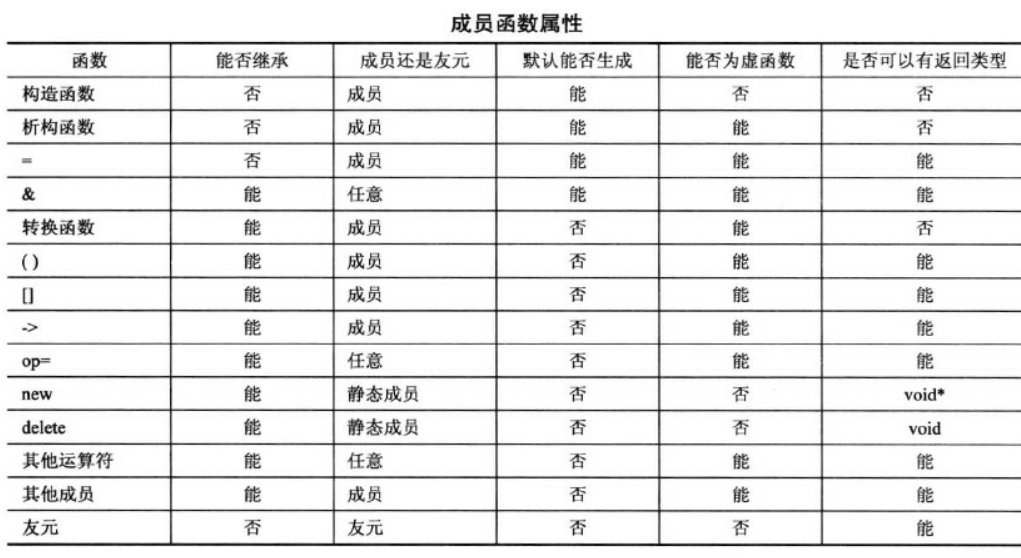
访问控制
C++ 有 3 个关键字用于访问控制,它们分别是 private、public、protected。下面列表说明:
1
访问控制符用于修饰类中的名称(变量、常量、方法等)
访问控制符对一下几个作用域进行了不同的设定:类本身(类内)、派生类、类对象(类外)、友元。
| public | protected | private | |
| 类本身 | 可访问 | 可访问 | 可访问 |
| 类对象 | 可访问 | 不可 | 不可 |
| 派生类 | 可访问 | 可访问 | 不可 |
| 友元 | 可访问 | 可访问 | 可访问 |
private 数据成员实现了数据隐藏。数据隐藏(将数据放在私有部分中)是一种封装,数据隐藏不仅可以防止直接访问数据,还可让开发者(类的用户)无需了解数据时如何表示的。 从使用类的角度看,只需要知道成员函数接收什么样的参数以及返回什么类型的值,原则是将实现细节从接口设计中分离出来。如果以后找到了更好的实现数据表示成员函数细节的方法, 可以对这些细节进行修改,而无需修改程序接口,这些修改对于使用者而言是隐藏的,从而使程序维护起来更容易
继承方式有三种:public、protected、private
1
2
访问控制符的访问由窄变宽依次是:
private < protected < public
继承之后的权限以最窄(严格)的为准,具体见下面说明:
1
2
父类的友元是不可继承的。
因为友元不属于类成员
- 公有继承: 不改变从父类继承来的访问控制符
- 保护继承: 从父类继承来的 public 变成 protected,而父类的 private 和 protected 不变
- 私有继承: 从父类继承来的所有名称都变成 private
继承过来之后,这些关键字对类本身、类对象。派生类、友元的作用域请参考前面的说明。
1
2
最好对类数据成员采用私有访问控制,不要使用保护访问控制;
同时通过基类方法使派生类能够访问基类的数据
然而,对于成员函数来说,保护访问控制很有用,它让派生类能够访问公众不能使用的内部函数。
成员函数
public 成员函数是类对类内类外(类对象)和子类访问数据的公开接口,而 protected 是对子类和类内公开接口, 而 private 只是类内的接口。
1
私有成员函数的主要价值在于:通过使用函数调用,而不是每次重新输入相同代码。
构造函数
数据部分的访问状态为私有的,这意味着程序不能直接访问数据成员,只能通过成员函数来访问。因此需要设计合适的成员函数才能成功 第将对象初始化。
为此,C++ 提供了一个特殊的成员函数—–类构造函数,专门用于构造新对象,将值赋给它们的数据成员。构造函数的原型没有返回值 (也不用 void),而且名称和类名相同,其他的和普通成员函数一样。当然构造函数也可以重载。
无法使用对象来调用构造函数,因为在构造函数构造出对象之前,对象不存在的。因此构造函数被用来创建对象,而不能透过对象来调用。
1
默认构造函数
默认构造函数是在未提供显式初始值时,用来创建对象的构造函数。不过需要注意的是,当且仅当没有定义任何构造函数时,编译器才会 提供默认构造函数。如此,为类定义了构造函数后,程序员就必须为它提供默认构造函数,否则不带参数的创建对象会出错。
1
程序员自定义默认构造函数的方式有两种:
- 给已有的构造函数的所有参数提供默认值。如
1
stock(const string & co = "Error", int n = 0, double pr = 0.0);
- 通过函数重载定义一个没有参数的构造函数。如
1 2 3 4 5 6 7
Stock::Stock() { company = "no name"; shares = 0; share_val = 0.0; total_val = 0.0; }
提示:在设计类时,通常应提供对所有类成员做隐式初始化的默认构造函数。
在 C++11 中可以将列表初始化(如结构体初始化)语法用于类,只要提供与某个构造函数的参数列表匹配的内容,并用大括号将它们括起来。
析构函数
析构函数比构造函数更特殊,其名称是在类名前加上 ~。析构函数没有参数和返回值,也不允许重载。
由于在类对象过期时析构函数将自动被调用,因此必须有一个析构函数。如果程序员没有提供析构函数,编译器将隐式地声明一个默认析构函数,并在发现导致对象被删除的代码后,提供默认析构函数的定义。不过,
1
在构造函数中使用了 new,必须要自定义一个析构函数中使用 delete ;奥释放
什么时候应调用析构函数呢?这由编译器决定,通常不应在代码中显式地调用析构函数(在定位 new 运算符时有例外)。
- 自动存储类对象
如果创建的是静态存储类对象,则其析构函数将在程序执行结束时自动被调用。
- 自动存储类对象
如果创建的是自动存储对象,则其析构函数将在程序执行代码块时自动被调用。
- new 对象
如果对象是通过 new 创建的,则它将驻留在栈内存货自由存储区中,当使用 delete 来释放内存时,其析构函数将自动被调用。
- 临时对象
程序可以创建临时对象来完成特定的操作,在这种情况下,程序将在结束对该对象的使用时自动调用其析构函数。
1
2
提示:如果既可以通过初始化,也可以通过赋值来设置对象的值,
则应蚕蛹初始化方式。通常这种方式效率更高(减少临时对象的创建)。
const 成员
const 用法请参考《Cpp 常用关键字总结》,这里只给出以下原则:
1
2
要像尽可能将 const 引用和指针用作函数形参一样,
只要类方法不修改调用对象,就应将其声明为 const。
静态成员函数
可以将成员函数声明为静态的(函数声明必须包包含关键字 static)。这样做有两个重要的后果:
- 不能使用 this 指针
不能通过对象调用静态成员函数:实际上,静态成员函数甚至不嫩使用 this 指针。如果静态成员函数是在公有部分声明的。则可以使用类 名和作用域解析运算符来调用它。例如:
1
2
3
4
原型如下:
static int HowMany(){ return num_strings; }
调用它的方式如下:
int count = String::HowMany();
- 只能使用静态数据成员
由于静态成员函数不与特定的对象相关联。因此只能使用静态数据成员。
特殊成员函数
如果累中没有自定义以下成员函数,则编译器会自动特供如下特殊成员函数:
- 默认构造函数
- 默认析构函数
- 复制构造函数
- 赋值运算符
- 地址运算符
何时调用复制构造函数:
- 新建一个对象并将其初始化为同类现有对象时,复制构造函数都被调用。
- 每当程序生成对象副本时,编译器都将使用复制构造函数。具体说来,当函数按值传递对象或函数返回对象时,都将使用复制构造函数。
默认复制构造函数的功能
默认的复制构造函数组个复制非静态成员(因为静态成员是同类所有对象共享的,不需要每个对象都创建),复制的是成员的值,这种被 称为浅复制。当构造函数中使用了 new 时,则需要深度复制,也就是说必须自定义复制构造函数。
实现类成员函数
成员函数定义与常规函数定义非常相似(除内联函数在类外定义需要额外加 inline 关键字外,其他的非常规函数关键字都不能再在定义时 重复),它们有函数头和函数体,也可以有返回类型和参数。但是它们还有两个特殊的特征:
- 定义成员函数时,使用作用域解析运算符(::)来标识函数所属的类;
- 类方法可以访问类的 private 组件。
this 指针
this 指针指向用来调用成员函数的对象(this 被作为隐藏参数传递给方法)。一般来说,所有类方法都将 this 指针设置为调用它的 对象的地址。
1
注意
每个成员函数(包括构造函数和析构函数)都有一个 this 指针。this 指针指向调用对象。如果方法需要引用整个调用对象,则可以使用 表达式 *this。在函数括号后使用 const 限定符将 this 限定为 const,这样讲不能使用 this 来修改对象的值。
然而,要返回的并不是 this,因为 this 是对象的地址,而是对象本身,即 this(将解除引用运算符 用于指针,将得到指针指向的 值)。
对象数组
对象数组的声明定义和普通数组是一样的,只不过初始化的时候可以使用显式构造函数或列表初始化。
1
初始化对象数组的方案是:
首先使用默认构造函数创建数组元素,然后花括号中的构造函数将创建临时对象,然后将临时对象的内容复制到相应的元素中。
1
注意:要创建类对象数组,则这个类必须有默认构造函数。
重载运算符
要重载运算符,需使用被称为运算符函数的特殊函数形式。其格式如下:
1
2
返回值 operator运算符(argument-list),如
Time operator+(const Time & t) const
运算符重载限制
多数 C++ 运算符都可以重载。重载运算符(有些例外情况)不必是成员函数,但至少有一个操作数是用户定义的类型。下面详细介绍 C++ 对用户自定义的运算符重载的限制:
- 操作数限制
重载后的运算符必须至少一个操作数是用户定义类型,这将防止用户为标准类型重载运算符。
- 句法规则限制
使用运算符时不能违反运算符原来的句法规则,如两目运算符不能重载为一目运算符。
- 运算符优先级限制
运算符重载不改变运算符本身的优先级
- 不能创建新运算符
- 不能重载下面的运算符
- sizeof
- . 成员运算符
- .* 成员指针运算符
- :: 作用域解析运算符
- ?: 条件运算符
- typeid 一个 RTTI 运算符
- const_cast 强制类型转换运算符
- dynamic_cast
- reinterpret_cast
- static_cast
- 下面的运算符只能通过成员函数进行重载
- = 赋值运算符
- () 函数调用运算符
- [] 下标运算符
- -> 通过指针访问类成员的运算符
可重载的运算符见下图:

重载运算符的多种方式
1
2
Time operator+(const Time U t) const 和
friend Time operator+(const Time & ta, const Time & t2);
这两种格式是等效的,所以只能选择其中的一种格式,否则被视为二义性。
- 对于成员函数版本:
一个操作数通过 this 指针隐式地传递,另一个操作数作为函数参数显式地传递
- 对于友元版本来说:
两个操作数都作为参数传递。
友元
C++ 控制对类对象私有部分的访问,通常,公有成员函数是提供的唯一访问途径。但友元提供了另外一种访问途径。友元有 3 种:
- 友元函数
- 友元类
- 友元成员函数
通过让函数成为类的友元,可以赋予该函数与类的成员函数相同的访问权限。
前面提到了重载运算符,那是其中的一种方式,该方式只能使用如 A = B * 2.75 形式的调用方式,如果使用如 A = 2.75 * B的方式是 错误的,因为 2.75 不是对象,不能调用成员方法。如何解决这个问题,友元函数提供了解决问题的方法。
大多数运算符都可以通过成员或非成员(友元)函数来重载。非成员函数不是由对象调用的,它使用的所有值(包括对象)都是显式参数。 要想使用非成员函数访问类的私有成员,应该将其声明为友元函数。
创建友元
创建友元的第一步是将其原型放在类声明中,并在原型声明前加上关键字 friend,如
1
friend Time operator*(double m, const Time & t);
该原型意味着以下两点:
- 虽然 operator*()函数是在类声明中声明的,但它不是成员函数,因此不能使用成员运算符来调用。
- 虽然 operator*()函数不是成员函数,但它与成员函数的访问权限相同。
第二步是编写函数定义。因为它不是成员函数,所以不要使用 Time:: 限定符。另外,不要在定义中使用关键字 friend(因为 friend 是 相对于类而言,既然在声明中已经使用,而且在定义时不能使用类限定符,这连个特征完全可以区别于成员函数和普通函数,所以基于简洁 的宗旨,是不能再用 friend 的)。
1
友元是否有悖于 OOP
友元函数应看作类的扩展接口的组成部分。而且,只有类声明可以决定哪一个函数时友元,因此类声明仍然控制了哪些函数可以访问私有 函数。总之,类方法和友元只是表达类接口的两种不同机制。
1
2
提示:如果要为类重载运算符,并将非类的项作为其第一个操作数,
则可以用友元函数来反转操作数的顺序。
类型转换
可以将类定义成与基本类型或另一个类(典型的是基类和派生类)相关,使得从一种类型转换为另一种类型是有意义的。在这种情况下, 程序员可以指示 C++ 如何自动进行转换,或通过强制类型转换来完成。
隐式转换
如果定义了一个参数的构造函数,当定义对象或赋值时,只要参数匹配,就可以进行隐式转换。如
1
2
Stonewt mycat; //create a Stonewt object
mycat = 19.6; //use Stonewt(double) to convert 19.6 to Stonewt
程序将使用构造函数 Stonewt(double) 来创建一个临时的 Stonewt 对象,并将 19.6 作为初始化值,随后,采用逐成员赋值的方式将 临时对象的内容复制到 myCat 中。这就是隐式转换,因为它是自动进行的,而不需要显式强制类型转换。
1
只有接受一个参数的构造函数才能作为转换函数
如何关闭这种自动隐式转换的特性?
1
2
3
C++ 新增了关键字 explicit 用于关闭这种自动转换特性
可以这样声明构造函数:
explicit Stonewt(double lbs); // no implicit conversions allowed
不过个人建议,最好使用关键字 explicit 进行限定单个参数的构造函数,以免发生以下隐式转换:
- 将 Stonewt 对象初始化为 double 值时
- 将 double 值赋给 Stonewt 对象时
- 将 double 值传递给接受 Stonewt 参数的函数时
- 返回值被声明为 Stonewt 的函数视图返回 double 值时
- 在上述任一一种情况下,使用可转换为 double 类型的内置类型时(当且仅当转换不存在二义性时,才会进行这种二步转换)
转换函数
前面的隐式转换已经提到,构造函数只用于从某种类型到类类型的转换(因为构造函数就是为了创建类对象的)。要进行相反的转换,必须 使用特殊的 C++ 运算符函数——转换函数
转换函数是用户定义的强制类型转换,可以像使用强制类型转换那样使用它们。
创建转换函数
要转换为 typeName 类型,需要使用这种形式的转换函数:
1
2
operator typeName();
例如,operator double();
请注意以下几点(事实上,typeName 已经制定了返回类型的信息):
- 转换函数必须是类方法(隐式传递 this 指针为参数)
- 转换函数不能指定返回类型
- 转换函数不能有参数(通过 this 已经传入,没必要)
注意事项:
- 当类只定义了一种转换时,编译器会自动应用类型转换
- 当类定义了两种或更多的转换时,仍可以用显式强制类型转换来指出要使用哪个转换函数(语法和 C 语言的强制类型转换一样的),但 编译器不会自动应用类型转换
动态内存
有些情况下,内存需要多少是很难事先确定的,只能按照最大需求申请,这样必然造成大量的浪费,所以最好是能在运行时根据需要进行申请。 C++ 使用 new 和 delete 运算符来动态控制内存。遗憾的是,在类中使用这些运算符将导致许多新的编程问题。在这种情况下,析构函数 是必不可少的。
当对象过期时,构造函数中的指针也将过期,该指针会被自动释放,但其指向的内存仍被分配,除非使用 delete 将其释放。删除对象可以 释放对象本身占用的内存,但并不能自动释放属于对象成员的指针指向的内存。因此,
1
2
必须使用析构函数,在析构函数中使用 delete 语句可确保对象过期时,
由构造函数使用 new 分配的内存被释放。
注意事项:
在构造函数中使用 new 来分配内存时,必须在相应的析构函数中使用 delete 来释放内存。如果使用 new[](包括中括号)来分配内存,则 应使用 delete[](包括中括号)来释放内存。
深度(显式)复制构造函数
当构造函数使用了 new,则默认的复制构造函数的浅复制只复制了指针变量的地址,而没有复制该指针指向的内存中的值,而该对象并不能 访问其他对象中的值(或者已经被释放),如此必然造成访问错误。解决这一问题办法是,提供一个显式的复制构造函数, 该构造函数的参数为本类形式对象。
1
警告:
如果类中包含了使用 new 初始化的指针成员,应当定义一个复制构造函数,以复制指向的数据,而不是指针,这被称为深度复制。 复制的另一种形式(默认复制构造函数提供的成员复制或浅复制)只是复制指针值。浅复制仅浅浅地复制指针信息,而不会深入“挖掘” 以复制指针引用的结构。具体见下面的例子:
1
2
3
4
5
6
7
StringBad::StringBad(const StringBad & st)
{
num_strings++;
len = st.len;
str = new char [len + 1];
std::strcpy(str,st.str);
}
显式赋值函数
与默认复制构造函数相似,赋值运算符的隐式实现(默认赋值函数)也只是对成员进行组个复制,如果成员本身就是类对象,则程序将使用 为这个类定义的赋值运算符来复制该成员,但静态数据成员不受影响。
当构造函数中使用了 new,则默认的赋值函数将出现问题(原因见前面的复制构造函数),解决办法是提供显式的赋值运算符 (进行深度复制)定义。其实现与复制构造函数相似,但也有一些区别:
- 由于目标对象可能引用了以前分配的数据,所以函数应使用 delete[] 来释放这些数据
- 函数应当避免对象赋给自身;否则,给对象重新赋值前,释放内存操作可能删除对象的内容。
- 函数返回一个指向调用对象的引用
通过返回一个对象,函数可以像常规赋值操作那样,连续进行赋值。例如:
1
2
3
4
5
6
7
8
9
10
StringBad & StringBad::operator=(const StringBad & st)
{
if (this == &st)
return *this;
delete [] str;
len = st.len;
str = new char [len + 1];
std::strcpy(str,st.str);
return *this;
}
在构造函数中使用 new 时的注意事项
根据前面的描述,已经知道了使用 new 初始化对象的指针成员时必须特别小心。具体说来,应当这样做:
- 如果在构造函数中使用 new 来初始化指针成员,则应在析构函数使用 delete
- new 和 delete 必须相互兼容,new 对应于 delete,new[] 对应于 delete[]
- 如果有多个构造函数,则必须以相同的方式使用 new,要么都带中括号,要么都不带。因为只有一个析构函数,所有的构造函数都必须 与它兼容。然而,可以在一个构造函数中使用 new 初始化指针,而在另一个构造函数中将指针初始化为空(0 或 C++11 中的 nullptr), 这是因为 delete (无论是带中括号还是不带中括号的)可以用于空指针。
- 应定义一个复制构造函数,通过深度复制将一个对象初始化为另一个对象。具体说来,复制构造函数应分配足够空间来存储复制的数据, 并复制数据,而不仅仅是数据的地址。另外,还应该更新所有受影响的静态类成员。
- 应当定义一个赋值运算符,通过深度复制将一个对象复制给另一个对象。具体说来,该方法应完成这些操作:检查自我赋值的情况,释放 成员指针以前指向的内存,复制数据而不仅仅是数据的地址,并返回一个指向调用对象的引用。
定位 new 运算符
new 负责在堆中找到一个足以能够满足要求的内存块。new 运算符还有另一种变体,被称为定位 new 运算符, 它让你能够指定要使用的位置(可以看做是已经分配的内存空间的二次分配),程序员可能使用这种特性来设置其内存管理规程、 处理需要通过特定地址进行访问的硬件或在特定位置创建对象。
定位 new 运算符的另一种用法是:将其与初始化结合使用,从而将信息放在特定的硬件地址处。基本上, 它只是返回传递给它的地址,并将其强制转换为 void *,以便能够赋给任何指针类型。
1
定位 new 运算符的例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
#include <new>
//使用 定位 new 运算符必须包含该头文件
char buffer1[50];
char buffer2[500];
struct chaff
{
char dross[20];
int slag;
};
chaff *p1, *p2;
int *p3, *p4;
p1=new chaff; //place structure in heap
p3=new int[20]; //place int array in heap
p2=new (buffer1) chaff; //place structure in buffer1
p4=new (buffer2) int[20]; //place int array in buffer2
1
使用定位 new 运算符注意事项
- 用定位 new 运算符分配的内存不能使用 delete 释放。事实上, 必须全部先显式调用析构函数(内建类型除外),最后释放一次分配 (可能通过 new 分配,也可能自动分配)的内存就好(定位 new 运算符属于二次分配)。
- 程序员要把一块大的已分配的内存空间使用定位 new 运算符化成多个小块时,必须使用其中的不同的内存单元,需要提供位于缓冲区 的不同地址,并确保这些小块没有重叠的区域,否则会相互覆盖。
注意事项,具体见下面的例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
#include <iostream>
#include <string>
#include <new>
using namespace std;
const int BUF = 512;
class JustTesting
{
private:
string words;
int number;
public:
JustTesting(const string & s = "Just Testing",int n = 0)
{
words = s;
number = n;
cout << words << " constructed\n";
}
~JustTesting()
{
cout << words << " destroyed\n";
}
void Show() const
{
cout << words << ", " << number << endl;
}
};
int main()
{
char * buffer = new char[BUF]; // get a block of memory
JustTesting *pc1,*pc2;
pc1 = new (buffer) JustTesting; // place object in buffer
pc2 = new (buffer) JustTesting("Heap1",20) // place object on heap
cout << "Memory block addresses:\n" << "buffer: "
<< (void *) buffer << " heap: " << pc2 << endl;
cout << "Memory contents:\n";
cout << pc1 << ": ";
pc1->Show();
cout << pc2 << ": ";
pc2->Show();
JustTesting *pc3,*pc4;
// fix placement new location
pc3 = new (buffer + sizeof(JustTesting)) JustTesting("Better idea",6);
pc4 = new JustTesting("Heap2",10);
cout << "Memory contents:\n";
cout << pc3 << ": ";
pc3->Show();
cout << pc4 << ": ";
pc4->Show();
delete pc2; // free Heap1
delete pc4; // free Heap2
// explicitly destroy placement new object
pc3 -> ~JustTesting(); // destroy object pointed to by pc3
pc4 -> ~JustTesting(); // destroy object pointed to by pc4
delete [] buffer; // free buffer
cout << "Done\n";
return 0;
}
类继承
面向对象编程的主要目的之一是提供可重用的代码。重用经过测试的代码比重新编写代码要好得多。使用已有的代码可以节省时间,由于 已有的代码被使用和测试过,一次有助于避免在程序中引入错误。另外,必须考虑的细节越少,使越能专注于程序的整体策略。
1
2
3
友元不是成员函数,不能使用作用域解析运算符来调用,也不能继承。
派生类使用基类友元的方法是:
使用强制类型转换成基类,以便匹配原型时能够选择正确的函数
函数库
传统的 C 函数库通过预定义、预编译的函数提供了可重用性。然而,函数库也有局限性,除非产商提供了库函数的源代码(通常是不提供的), 否则将无法根据自己特定的需求,对函数进行扩展或修改,而必须根据库函数的情况修改自己的程序,即使厂商提供了源代码,在修改时 也有一定的风险,如不经意地修改了函数的工作方式或改变了库函数之间的关系。
类继承概述
C++ 类提供了更高层的重用性,目前,很多厂商提供了类库,类库由类声明和实现构成,因为类组合了数据表示和类方法,因此提供了比 函数库更加完整的程序包。比修改源代码更好的方法来扩展和修改类的方法有类继承。它能够从已有的类派生出新的类,而派生类继承了 原有类(称为基类)的特征,包括方法,但不影响对原来的类的使用。
1
下面是可以通过继承完成的一些工作:
- 可以在已有类的基础上添加功能(新方法)
- 可以给类添加数据(新数据成员)
- 可以修改类方法的行为(函数重定义)
当然,可以通过赋值原始类代码,并对其进行修改完成上述工作。但继承机制只需提供新特性,甚至不需要范文源代码就可以派生出类 (只需要添加类声明或修改原头文件)。因此,如果购买的类库只提供了类方法的头文件和编译后代码,仍可以使用库中的类派生出新的类。 而且可以在不公开实现的情况下将自己的类分发给其他人,同时允许其他人在类中添加新特性。
什么不能被继承
基类的构造函数,析构函数,赋值运算符。
派生类
派生出的类将具有以下特征:
- 派生类对象存储了基类的数据成员(派生类继承了基类的实现);
- 派生类对象可以使用基类的方法(派生类继承了基类的接口)。
需要在继承特性中添加:
- 派生类需要自己的构造函数
- 派生类可以根据需要添加额外的数据成员和成员函数
- 构造函数必须给新成员(如果有)和继承的成员提供数据。
派生类构造函数
派生类不能直接访问基类的私有成员,而必须通过基类方法进行访问。因此,派生类构造函数必须使用基类构造函数。创建派生类对象时, 程序首先创建基类对象。从概念上说,这意味着基类对象应当在程序进入派生类构造函数之前被创建。C++ 使用成员初始化列表语法来 完成这种工作,
1
派生类构造函数例子:
1
2
3
4
5
6
// 新旧数据成员应都在派生类的构造函数列表中,并且旧数据成员用基类构造函数来初始化
RatedPlayer::RatedPlayer( unsigned int r, const string & fn, const string & ln, bool ht)
: TableTennisPlayer(fn, ln, ht)
{
rating = r; // 对新的数据成员初始化
}
必须首先创建基类对象,如果不调用基类构造函数,程序将使用默认的基类构造函数,如下:
1
2
3
4
5
RatedPlayer::RatedPlayer( unsigned int r, const string & fn, const string & ln, bool ht)
//: TableTennisPlayer()
{
rating = r; // 对新的数据成员初始化
}
1
有关派生类构造函数的要点如下:
- 首先创建基类对象(建初始化列表)
- 派生类构造函数应通过成员初始化列表将基类信息传递给基类构造函数。
- 派生类构造函数应初始化派生类新增的数据成员
释放对象的顺序与创建对象的顺序相反,即首先执行派生类的析构函数,然后自动调用基类的析构函数(类似栈)。
派生类和基类之间的特殊关系
派生类与基类支架有一些特殊关系,列举如下:
- 派生类对象可以使用基类的非私有方法
- 基类指针可以在不进行显式类型转换的情况下指向派生类对象。
- 基类引用可以在不进行显式类型转换的情况下引用派生类对象
- 但是,基类指针或引用只能用于调用基类方法
以上第2,3中基类和派生类的位置反过来是不成立的,因为这意味着派生类(指针或)引用能够为基对象调用派生类方法,这样讲出现问题。 毕竟,基类对象中不存在某些派生类独有的方法。为什么编译器不根据对象来调用方法呢?
1
2
编译器是根据指针和引用类型来调用方法
而不是根据指针或引用所指向的对象类型
有关使用基类方法的说明
以公有方式派生的类对象可以通过多种方式来使用基类的方法。
- 派生类对象自动使用继承而来的非私有基类方法(如果派生类没有重定义该方法)
- 派生类的构造函数自动调用基类的构造函数(但需要初始化列表)
- 派生类的构造函数自动调用基类的默认构造函数,如果初始化列表中没有指定基类构造函数
- 派生类构造函数显式地调用成员初始化列表指定的基类构造函数
- 派生类方法可以使用作用域解析运算符来调用公有的和受保护的基类方法
- 派生类的友元函数可以通过强制类型转换,将派生类引用或指针转换为基类引用或指针,然后使用该引用或指针来调用基类的友元函数。
类与类之间的关系
类与类之间的关系有:包含(组合或层次化),公有继承、私有或保护继承,多重继承。
公有继承:is-a 关系
C++ 有 3 种继承方式:公有继承、保护继承和私有继承。
1
公有继承建立了一种 is-a 关系
即派生类对象也是一个特殊的基类对象,可以对基类对象执行的任何操作,也可以对派生类对象执行。如,香蕉是一种水果,香蕉可以从、 水果类中派生出来。
1
为阐明 is-a 关系,下面列举一些与该模型不符的例子
- 公有继承不建立 has-a 关系。如,午餐有水果
- 公有继承不能建立 is-like-a 关系(它不采用明喻)。如,帝国主义是纸老虎
- 公有继承不建立 is-implemented-as-a(用……来实现) 关系。
如,栈可以用数组来实现,但栈不是数组。从 Array 类派生出 Stack 类是不合适的。正确的方法是,通过让栈包含一个私有 Array 对象 成员来隐藏数组实现
- 公有继承不建立 use-a 关系。
如,计算机可以使用打印机。但从 computer 类派生出 Printer 类(或反过来)是没有意义的。然而,可以使用友元函数或类来处理 Printer 和 Computer 对象之间的通信。
1
继承和动态内存分配的关系和注意事项请参考 new
多态公有继承
这里的多态是指同一个方法在派生类和基类中的行为是不同的,也就是说,方法的行为应取决于调用该方法的对象,即同一个方法的行为 随上下文而异。有两种重要的机制可用于实现多态公有继承:
- 在派生类中重新定义基类的方法
- 基类使用虚方法
如果没有使用 virtual 关键字 ,程序将根据引用类型或指针类型选择方法;如果使用了 virtual,程序将根据引用或指针指向的对象 的类型来选择方法。当然也可以使用类解析运算符明确指出调用的是哪个方法。
因此,经常在基类中将派生类会重新定义的方法声明为虚方法。方法在基类中声明为虚的后,它在派生类中将自动成为虚方法。然而,在 派生类中使用关键字 virtual 来再次指出哪些函数是虚函数也不失为一个号方法。
1
2
最好为基类声明虚析构函数。以确保释放派生类对象时,
按正确的顺序调用析构函数
在派生类中,标准技术是使用作用域解析运算符来调用基类方法
1
为何需要虚析构函数?
这是由编译器根据指针或引用类型(而不是指向的对象类型)来调用方法的规则造成的,如果不适用虚析构函数,则将只调用对应于指针 类型的析构函数而不调用基类的析构函数。
1
2
3
基类指针或引用可以指向任意派生出的类对象(即使多层次派生),
称之为“隐式向上强制转换”
但是,反过来(向下强制转换)是不允许的
隐式向上强制转换使基类指针或引用可以指向基类对象或派生类,因此需要动态联编。C++ 使用虚成员函数来满足这种需求。
静态联编和动态联编
编译器对非虚函数使用静态联编,对虚函数使用动态联编。
使用非虚函数有两方面的好处:
- 效率更高
- 指出不要重新定义该函数(虽然不能组织这样做)
虚函数的工作原理
通常,编译器处理虚函数的方法是:给每个对象添加一个隐藏成员来保存一个指向函数地址数组的指针。这种数组称为虚函数表。虚函数 表中存储了为类对象进行声明的虚函数的地址。但需要注意的是:
1
2
3
无论类中包含的虚函数是一个还是多个,
都只需要在对象中添加一个地址成员,
只是表的大小不同而已
使用虚函数的成本如下:
- 每个对象都将增大,增大量为存储地址的空间
- 对于每个类,编译器都创建一个虚函数地址表(数组)
- 对于每个函数调用,都需要执行一项额外的操作,即到表中查找特定虚函数地址
关于虚函数和重定义的几点说明
- 派生类不继承基类的构造函数,所有将类构造函数声明为虚的没什么意义
- 析构函数应当为虚函数,除非类不用做基类(也可声明为虚函数,只是效率问题)
即使基类不需要显式析构函数提供服务,也不应依赖默认析构函数,而应提供虚析构函数,即使他不执行任何操作。
- 友元不能是虚函数
友元不是类成员,不能是虚函数。如果由于这个原因引起了设计问题,可以通过让友元函数使用虚成员函数来解决。
- 重新定义将隐藏方法
重新定义继承的方法并不是重载。如果在派生类中重新定义函数,将不是使用相同的函数特征标覆盖基类声明, 而是隐藏所有同名的基类方法,不管参数特征标如何。
如果重新定义继承的方法,应确保与原来的原型完全相同,但如果赶回类型是基类引用或指针,则可以修改为指向派生类的引用或指针 (被称为返回类型协变)
1
2
如果基类方法声明被重载了,则应在派生类中重新定义所有的基类版本。
否则,同名的其他基类方法将被隐藏而不能被派生类使用
多重继承
多重继承(MI)描述的是,有多个直接基类的类,与单继承一样,公有MI(必须使用关键字 public 来限定每一个基类,类似指针) 表示的也是 is-a 关系。
1
MI 可能会带来很多新问题,主要有两方面:
- 从两个不同的基类继承同名方法
这个问题实际上导致函数调用的二义性。可以使用类作用域解析运算符来明确指出使用的方法
- 从两个或更多相关基类那里继承同一个类的多个实例
这个问题的实质是,基类指针或引用指向派生对象使用基类方法时将出现二义性(公有继承可以这样隐式这样转换)。 因为这样的继承将出现多个同样的基类副本。
1
第一种解决方法:虚基类
虚基类使得从多个类(它们的基类相同)派生出的对象只继承一个基类对象。可以通过在类声明中使用关键字 virtual(类似关键字重载) 。例如,
1
2
3
4
class Singer : virtual public Worker {...};
class Waiter : public virtual Worker {...};
然后
class SingingWaiter : public Singer, public Waiter {...};
对于使用虚基类,派生类即使不使用类作用域解析运算符,也不会导致二义性,因为这种情况下,编译器采用就近原则(派生类中的名称优先于直接或间接祖先类中 的相同名称,类似“局部变量”规则)。但是,如果没有派生关系,将出现二义性,而且这种二义性与访问控制规则无关(一个私有,一个公有也算二义性)。
1
2
3
4
非虚基类多重继承产生多个基类副本的原因是:
构造函数的自动调用,而构造函数的调用将创建对象实体。
从而,多个副本产生了。
但是虚基类阻断了这种自动调用机制。
接着,必须以不同的方式写一些代码。另外,使用虚基类还可能需要修改已有的代码。
- 构造函数
C++ 在基类是虚的时,精致信息通过中间类自动传递给基类。所以所有的类都要在初始化列表中初始化,否则将启用默认构造函数。例如:
1
2
SingingWaiter (const Worker & wk, int p = 0, int v = Singer::other)
: Waiter(wk, p), Singer(wk, v) {}
虚基类总结:
在祖先相同时,使用 MI 必须引入虚基类,并修改构造函数初始化列表的规则。另外,如果在编写这些类时没有考虑到 MI ,则还可能需要重新编写它们。 原因见前面的分析。
1
将所有的数据组件(最好是方法)都设置为保护的,而不是私有的
例子如下:
1
workermi.h 头文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
#indef WORKERMI_H
#define WORKERMI_H
#include <string>
class Worker
{
private:
std::string fullname;
long id;
protected:
virtual void Data() const;
virtual void Get();
public:
Worker() : fullname("no one"), id(01) {}
Worker(const std::string & s, long n)
: fullname(s), id(n) {}
virtual Worker() = 0;
virtual void Set() = 0;
virtual void Show() = 0;
};
class Waiter : virtual public Worker
{
private:
int panache;
protected:
void Data() const;
void Get();
public:
Waiter() : Worker(), panache(0) {}
Waiter(const Worker & wk, int p = 0)
: Worker(wk), panache(p) {}
void Set();
void Show() const;
};
class Singer : virtual public Worker
{
protected:
enum {other, alto, contralto, soprano,
bass, baritone, tenor};
enum {Vtypers = 7};
void Data() const;
void Get();
private:
static char *pv(Vtypers);
int voice;
public:
Singer() : Worker(), voice(other) {}
Singer(const StringBad::String & s, long n, int v = other)
: Worker(wk), voice(v) {}
void Set();
void Show() const;
};
class SingingWaiter : public Singer, public Waiter
{
protected:
void Data() const;
void Get();
public:
SingingWaiter() {}
SingingWaiter(const std::string & s, long n, int p = 0, int v = other)
: Worker(s,n), Waiter(s,n,p), Singer(s,n,v) {}
SingingWaiter(const Worker & wk, int p = 0,int v = other)
: Worker(wk), Waiter(wk,p),Singer(wk,v) {}
SingingWaiter(const Waiter & wt, int v = other)
: Worker(wt),Waiter(wt),Singer(wt,v) {}
SingingWaiter(const Singer & wt,int p = 0)
: Worker(wt),Waiter(wt,p),Singer(wt) {}
void Get();
void Show() const;
};
#endif
1
workermi.cpp 文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
#include "workermi.h"
#include <iostream>
using std::cout;
using std::cin;
using std::endl;
Worker::Worker() {}
void Worker::Data() const
{
cout << "Name: " << fullname << endl;
cout << "Employee ID: " << id << endl;
}
void Worker::Get()
{
getline(cin,fullname);
cout << "Enter worker's ID: ";
cin >> id;
while (cin.get() != '\0')
continue;
}
void Waiter::Set()
{
cout << "Enter Waiter's name: ";
Worker::Get();
Get();
}
void Waiter::Show() const
{
cout << "Category: Waiter\n";
Worker::Data();
Data();
}
void Waiter::Data() const
{
cout << "Panache rating: " << panache << endl;
}
void Waiter::Get()
{
cout << "Enter Waiter's panache rating: ";
cin >> panache;
while (cin.get()! != '\n')
continue;
}
char * Singer::pv(Singer::Vtypes) = {"other","alto","contralto",
"soprano","bass","baritone","tenor"};
void Singer::Set()
{
cout << "Enter Singer's name: ";
Worker::Get();
Get();
}
void Singer::Show() const
{
cout << "Category: Singer\n";
Worker::Data();
Data();
}
void Singer::Data() const
{
cout << "Vocal range: " << pv(voice) << endl;
}
void Singer::Get()
{
cout << "Enter number for Singer's vocal range::\n";
int i;
for(i = 0; i< Vtypers; i++)
{
cout << i << ": " << pv[i] << " ";
if ( i % 4 == 3 )
cout << endl;
}
if ( i % 4 != 0 )
cout << '\n';
cin >> voice;
while (cin.get( != '\n' )
continue;
}
void SingingWaiter::Data() const
{
Singer::Data();
Waiter::Data();
}
void SingingWaiter::Get()
{
Waiter::Get();
Singer::Get();
}
void SingingWaiter::Set()
{
cout << "Enter singing Waiter's name: ";
Worker::Get();
Get();
}
void SingingWaiter::Show() const
{
cout << "Category: singing waiter\n ";
Worker::Data();
Data();
}
1
workmi.cpp 文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
#include <iostream>
#include <cstring>
#include "workermi.h"
const int SIZE = 5;
int main()
{
using std::cin;
using std::cout;
using std::endl;
using std::strchr;
Worker * lolas[SIZE];
int ct;
for (ct = 0;ct < SIZE; ct++)
{
char choice;
cout << "Enter the Employee Category:\n"
<< "w: Waiter s: Singer "
<< "t: Singing Waiter q: quit\n";
cin >> choice;
while (strchr("wstq",choice) == NULL)
{
cout << "Please enter a w,s,t, or q:";
cin >> choice;
}
if (choice == 'q')
break;
switch(choice)
{
case 'w': lolas[ct] = new Waiter;
break;
case 's': lolas[ct] = new Singer;
break;
case 't': lolas[ct] = new SingingWaiter;
break;
}
cin.get();
lolas(ct)->Set();
}
cout << "\nHere is your staff:\n";
int i;
for (i = 0; i < ct; i++)
{
cout << endl;
lolas[i]->Show();
}
for (i = 0; i < ct; i++)
delete lolas[i];
cout << "Bye.\n";
return 0;
}
(组合或)包含对象成员的类
实际上,C++ 把类“视为”普通数据类型,所以箱普通类型一样使用类就可以了。
1
接口和实现
使用公有继承时,类可以继承接口,可能还有实现(基类的纯虚函数提供接口,但不提供实现)。获得接口是 is-a 关系的组成部分。而使用组合,类可以获得 实现,但不能获得接口,不继承接口是 has-a 关系的组成部分
包含主要解决的是 has-a 关系。对于 has-a 关系来说,类对象不能自动获得被包含对象的接口是一件好事:
- 可以使用包含类已经实现了的公有方法
- 不需要继承不需要的方法,也不需要了解不需要的部分
- 不需要像默写继承必须要实现的接口
- 不过被包含的类没有实现的接口可能对新类有意义,此时可考虑继承
has-a 关系
前面提到了实现 has-a 关系的一种方法组合。C++ 还有另一种 has-a 关系的途径—–私有继承。使用私有继承,基类的公有成员和保护成员都将成为 派生类的私有成员。这意味着基类方法将不会成为派生类对象公有接口的一部分,但可以在派生类的成员函数中使用它们。
1
2
3
私有继承可以可以在自己的接口中使用基类的非私有接口,
但自己的类对象不能使用基类的接口,从而达到了能使用并隐藏了基类方法,
因而可以只提供想提供的自己的方法(隐藏了基类细节)
私有继承和组合的比较
- 使用私有继承,类将继承实现,但只能在类内使用
- 私有继承提供的特性和包含相同:或得实现,但不获得接口
- 实现 has-a 关系的方法不同:
包含将对象作为一个命名的成员对象添加到类中,而私有继承对象作为一个未被命名的继承对象添加到类中。
- 使用原类方法的方式不同
使用包含时将使用对象名来调用方法,而使用私有继承时将使用类名和作用域解析运算符来调用方法。
1
如果私有继承要使用基类对象本身?如下:
可以使用强制类型转换,使用 *this,为避免调用构造函数创建新的对象,可使用强制类型转换来创建一个引用。例子如下:
1
2
3
4
const string & Student::Name() const
{
return (const string &) *this;
}
1
2
在私有继承(有别于公有继承)中,在不进行显式类型转换的情况下,
不能将指向派生类的引用或指针赋给基类引用或指针。
- 包含简单易懂,继承将会引发很多新问题需要处理(比如复制构造函数)
- 私有继承可以使用基类的保护部分,而包含不能
- 需要使用使用继承的情况是需要重新定义虚函数。派生类可以重新定义虚函数,但包含类不能。
综上得出结论:
通常,应使用包含来建立 has-a 关系;如果新类需要访问原有类的保护成员,或需要重新定义类函数,则应使用私有继承。
使用 using 重新定义访问权限
之前已经知道了类的访问控制以及继承的访问控制规则。当有时需要暂时破例(之后恢复之前的规则)。假设要让基类的方法在派生类(不论如何派生)外可用, 有一下方法可用破除访问限制:
- 定义一个使用该基类方法的派生类方法(公开方法使用类解析运算符调用非私有方法)
- 将函数调用包装在另一个函数调用中,即,使用一个 using 声明(就像名称空间那样)来指出派生类可以使用特定的基类成员,即使采用的是私有派生。
注意:using 声明只使用成员名——没有圆括号、函数特征标和返回类型。
初始化顺序
当初始化列表(构造函数头)包含多个项目时,这些项目被初始化的顺序为它们被声明的顺序,而不是它们在初始化列表中的顺序。
抽象基类
当两个类有很多共同点,但又不好使用单纯的继承,则可以将这些共同点放在一个虚基类中,然后分别继承这个抽象基类。
当类声明中包含纯虚函数(纯虚函数声明的结尾处为=0)时,则不能创建该类的对象。包含纯虚函数的类只能用作基类(被称为抽象基类)。
总之,在原型中使用 =0 指出类是一个抽象基类,在类中可以不定义该函数。抽象基类描述的是至少使用一个纯虚函数的接口,从抽象基类 派生出的类将根据派生类的具体特征,使用常规虚函数来实现这种接口(不再用 =0 ,但原型一致并且一定要定义)。
抽象基类理念
可以将抽象基类看做是一种必须实施的接口,抽象基类具体派生类覆盖其纯虚函数—–迫使派生类遵循抽象基类设置的接口规则。 如此,使用抽象基类使得组件设计人员能够制定“接口约定”,这样确保了从抽象基类派生的所有组件都至少支持抽象基类制定的功能。
类模板
可以通过 typedef 处理不同类型相同的需求。然而,这种方法有两个缺点:
- 每次修改类型时都需要编辑头文件
- 在每个程序中只能使用这种技术生成一种类型,即不能让 typedef 同时代表两种不同的类型。
C++ 的类模板为生成通用的类声明提供了一种更好的方法。模板提供参数化类型,即能够将类型名最为参数传递给接收方来建立类或函数 (类是创建对象的模板,而类模板是声明类的模板)。
类模板声明格式
1
2
3
template <class Type1, ...>(不推荐)
或
template <typename Type1, ...>
吧上面的声明放在类(普通类声明)之前,然后再类中使用其中的 Type 进行变量声明即可(相当于把其当做和 int 一般的已知类型)。实例如下:
1
2
3
注意:用到 Type 的地方必须带上 template<typename Type>放在函数头或是类头
因为它们是一个整体,而且不同的模板,其typeName 后的 Type 可以相同。
所以必须以一个整体出现才能表明其为特定模板。
1
2
3
4
5
template <typename Type>
bool Stack<Type>::push(const Type & item)
{
....
}
模板必须实例化或具体化(即用真实的类型替代 Type),而且必须实例化和模板放在一起,由于模板不是函数,它们不能单独编译。 仅仅在程序中包含模板并不能生成模板类,而必须请求实例。泛型标识符类似于变量,但它们必须是类型(而不能是数字等)。而且必须显式提供 (编译器无法推断出)所需的类型,这与常规函数模板是不同的,因为编译器可以根据函数的参数类型确定要生成哪种函数。请看下面例子:
1
stacktp.h 头文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
#ifndef STACKTP_H
#define STACKTP_H
template <typename Type>
class stack
{
private:
enum {MAX = 10;}
Type items[MAX];
int top;
public:
stack();
bool isempty();
boolisfull();
bool push(const Tupe & item);
bool pop(Type & item);
}
template <typename Type>
Stack<Type>::Stack()
{
top = 0;
}
template <typename Type>
bool Stack<Type>::isempty()
{
return top == 0;
}
template <typename Type>
bool Stack<Type>::isfull()
{
return top == MAX;
}
template <typename Type>
bool Stack<Type>::push(const Type & item)
{
if (top < MAX)
{
items[top++] = item;
return true;
}
else
return false;
}
template <typename Type>
bool Stack<Type>::pop(Type & item)
{
if (top > 0)
{
item = items[--top];
return true;
}
else
return false;
}
1
2
3
注意:类模板的目标是:
和常规类一样,通用所有技术
所以,只要遵守其声明规则就可以随心所欲的用就可以了
另外,C++标准制定者试图不改变以前的编程思想和编程习惯。使得函数模板和类模板极其相似,也就是说,函数模板的技术也可以迁移到类模板中来。更有趣 的是,设计者还试图统一普通函数和函数模板,所以普通函数的一切技术也可迁移过来。总之,九九归一,一通百通!比如,普通函数提供默认参数值, 模板函数提供部分实例化,模板函数可以被调用,普通函数可以重载等。
类模板之于类,类之于普通类型,只要具备扎实的普通类型和普通函数等知识,对 C++ 的特性或新特性想怎么来就怎么来,只怕觉得生疏、不顺手啊。
- 可以递归使用类模板(视为普通类,包含)
如 Array< Array<int,5>, 10> towdee;不过在模板语法中,维的顺序与等价的二维数组相反。
- 使用多个类型参数(毕竟类中用到的不止一种数据类型)
- 默认类型模板参数
如 template <typename T1, class T2 = int> class Topo {…}
1
2
3
4
5
虽然可以为类模板类型参数提供默认值,
但不能为函数模板参数提供默认值,因为
类模板必须具体化才生成类声明,而函数模板可以重载,
可能导致二义性。
然而,可以为非类型参数提供默认值,这对于类模板和函数模板都是适用的。
- 模板的具体化
类模板与函数模板很相似,因为可以有隐式实例化。显式实例化和显式具体化,它们统称为具体化。
1
2
模板以泛型的方式描述类,
而具体化是试用具体的类型生成类声明
- 隐式实例化
如 ArrayTP<int, 100> stuff; 古国编译器在需要对象之前,不会生成类的隐式实例化。
1
2
3
4
5
6
ArrayTP<double,10> * pt;
// a pointter, no object needed yet
pt = new ArrayTP<double,30>;
// now an object is needed
- 显式实例化
当试用关键字 template 并指出所需类型来声明类时,编译器将生成类声明的显式实例化。声明必须位于模板定义所在的名称空间。如
1
2
template class ArrayTP<string, 100>;
// generate ArrayTP<string, 100> class
在这种情况下,虽然没有创建或提及类对象,编译器也将生成类声明(包括方法定义)。和隐式实例化一样,也将根据通用模板来生成具体化。
- 显式具体化
显式具体化是特定类型(用于替换模板中的泛型)的定义。有时候,可能需要在为特殊类型实例化时,对模板进行修改,使其行为不同。在这种情况下,可以 创建显式具体化。当具体化模板和通用模板都与实例化请求匹配时,编译器将使用具体化版本。
1
2
具体化类模板定义如下:
template <> class ClassName<specialized-type-name> {...};
具体例子如下:
1
2
3
4
template <> class SortedArray<const char *>
{
...
}
- 部分具体化
前面是完全具体化,如果还保留了至少一个泛型,则为部分具体化。例如
1
2
3
4
5
// general template
template <class T1, class T2> class Pair {...}
// specialization with T2 set to int
template <class T1, class Pair<T1, int> {...}
1
2
如果有多个模板可供选择,
编译器将使用具体化程度最高的模板
- 模板可用作结构、类或模板类的成员。
- 将模板用作参数,如
1
2
template <template <typename T> class Thing>
class Grab
- 可以混合使用模板参数和常规参数,如
1
2
3
4
5
6
7
8
template <template <typename T> class Thing, typeName U, typeName V>
class Grab
{
private:
Thing<U> s1;
Thing<v> s2;
....
}
模板别名(C++11)
可以像以前一样使用 typedef 为模板具体化指定别名:
1
2
3
4
5
typedef std::array<double,12> arrd;
typedef std::array<int,12> arri;
arrd gallons;
arri days;
C++11 新玩法,使用模板提供一系列别名,如:
1
2
3
4
5
template<typename T>
using arrtype = std::array<T,12>;
arrtype<double> gallons;
arrtype<int> days;
总之, arrtype
C++11 允许将语法 using= 用于非模板,用于非模板时,这种语法与常规 typedef 等价:
1
2
3
4
typedef const char * pc1; //typedef syntax
using pc2 = const char *; // using = syntax
typedef const int *(*pa1) [10]; // typedef syntax
using pa2 = const int *(*) [10]; // using = syntax
模板类和友元函数
- 模板类的非模板友元函数
1
2
3
4
5
6
7
template <class T>
class HasFriend
{
public:
friend void counts();
// friend to all HasFriend instantiations
}
上述声明使 counts() 函数成为了模板所有实例化的友元。例如,它将是类 HasFriend
假设要为友元函数提供模板类参数如下: friend void report(HasFriend &); 这是不允许的!原因是,不存在 HasFriend 这样的对象,而只有特定的具体化, 如 HasFriend
1
2
3
4
5
6
template <class T>
class HasFriend
{
friend void report(HasFriend<T> &);
...
}
注意,report() 本身并不是模板类,而只是使用一个模板作参数,这意味着必须为要使用的友元定义显式具体化:
1
2
3
4
void report (HasFriend<short> &) {...}
// explicit specialization for short
void report (HasFriend<int> &) {...}
// explicit specialization for int
这两个 report() 函数分别是某个特定 HasFriend 具体化的友元。具体看下面示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
// frnd2tmp.cpp -- template class with non-template friends
#include <iostream>
using std::cout;
using std::endl;
template <typename T>
class HasFriend
{
private:
T item;
static int ct;
public:
HasFriend(const T & i) : item(i) {ct++;}
~HasFriend() {ct--; }
friend void counts();
friend void reports(HasFriend<T> &); // template parameter
};
// each specialization has its own static data member
template <typename T>
int HasFriend<T>::ct = 0;
// non-template friend to all HasFriend<T> classes
void counts()
{
cout << "int count: " << HasFriend<int>::ct << "; ";
cout << "double count: " << HasFriend<double>::ct << endl;
}
// non-template friend to the HasFriend<int> class
void reports(HasFriend<int> & hf)
{
cout <<"HasFriend<int>: " << hf.item << endl;
}
// non-template friend to the HasFriend<double> class
void reports(HasFriend<double> & hf)
{
cout <<"HasFriend<double>: " << hf.item << endl;
}
int main()
{
cout << "No objects declared: ";
counts();
HasFriend<int> hfi1(10);
cout << "After hfi1 declared: ";
counts();
HasFriend<int> hfi2(20);
cout << "After hfi2 declared: ";
counts();
HasFriend<double> hfdb(10.5);
cout << "After hfdb declared: ";
counts();
reports(hfi1);
reports(hfi2);
reports(hfdb);
// std::cin.get();
return 0;
}
- 模板类的约束模板友元函数
可以修改前一个示例,使友元函数本身成为模板,具体地说,为约束模板友元作准备,要使类的每一个具体化都获得与友元匹配的具体化。 这比非模板友元复杂些。
1
步骤(详细见后面的示例):
- 在类定义的前面声明每个模板函数。
1
2
template <typename T> void counts();
template <typename T> void report(T &);
- 在函数中再次将模板声明为友元。这些语句根据类模板参数的类型声明具体化
1
2
3
4
5
6
7
template <typename TT>
class HasFriend
{
friend void counts<TT>();
friend void report<>(HasFriend<TT> &);
};
声明中 <> 指出这是模板具体化,对于 report(), <> 可以为空,因为可以从函数参数推断出如下模板类型参数: HasFriend, 然而 也可以使用 report< HasFriend >(HasFriend &)
但是,counts() 函数没有参数,因此必须使用模板参数语法 () 来指明其具体化,还需要注意的是, TT 是 HasFriend 类的参数类型。
- 必须满足的第三个要求是,为友元提供模板定义。
具体例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
// tmp2tmp.cpp -- template friends to a template class
#include <iostream>
using std::cout;
using std::endl;
// template prototypes
template <typename T> void counts();
template <typename T> void report(T &);
// template class
template <typename TT>
class HasFriendT
{
private:
TT item;
static int ct;
public:
HasFriendT(const TT & i) : item(i) {ct++;}
~HasFriendT() { ct--; }
friend void counts<TT>();
friend void report<>(HasFriendT<TT> &);
};
template <typename T>
int HasFriendT<T>::ct = 0;
// template friend functions definitions
template <typename T>
void counts()
{
cout << "template size: " << sizeof(HasFriendT<T>) << "; ";
cout << "template counts(): " << HasFriendT<T>::ct << endl;
}
template <typename T>
void report(T & hf)
{
cout << hf.item << endl;
}
int main()
{
counts<int>();
HasFriendT<int> hfi1(10);
HasFriendT<int> hfi2(20);
HasFriendT<double> hfdb(10.5);
report(hfi1); // generate report(HasFriendT<int> &)
report(hfi2); // generate report(HasFriendT<int> &)
report(hfdb); // generate report(HasFriendT<double> &)
cout << "counts<int>() output:\n";
counts<int>();
cout << "counts<double>() output:\n";
counts<double>();
// std::cin.get();
return 0;
}
- 模板类的非约束模板友元函数
前面的约束模板友元函数是在类外面声明的模板的具体化。 int 类具体化获得 int 函数具体化,依此类推……通过在类内部声明模板, 可以创建非约束友元函数,即每个函数具体化都是每个类具体化的友元。对于非约束友元,友元模板类型参数与模板类型参数是不同的:
1
2
3
4
5
template <typename T>
class ManyFriend
{
template <typename C, typeName D> friend void show2(C &, D &);
}
1
该部分不详细讲解,请自行体会下面示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
// manyfrnd.cpp -- unbound template friend to a template class
#include <iostream>
using std::cout;
using std::endl;
template <typename T>
class ManyFriend
{
private:
T item;
public:
ManyFriend(const T & i) : item(i) {}
template <typename C, typename D> friend void show2(C &, D &);
};
template <typename C, typename D> void show2(C & c, D & d)
{
cout << c.item << ", " << d.item << endl;
}
int main()
{
ManyFriend<int> hfi1(10);
ManyFriend<int> hfi2(20);
ManyFriend<double> hfdb(10.5);
cout << "hfi1, hfi2: ";
show2(hfi1, hfi2);
cout << "hfdb, hfi2: ";
show2(hfdb, hfi2);
// std::cin.get();
return 0;
}
友元类
前面已经零散地讲过友元函数用于类的扩展接口,但类并非只能拥有友元函数,也可以将类作为友元。如此,友元类的所有方法都可以访问原始类的所有成员。 当然,也可以做更严格的限制,只将特定的成员函数指定为另一个类的友元。友元类有时是很高效的,比如电视机和遥控器。
1
2
声明友元的时候一定要注意 C++ 的原则:
先声明或定义之后才能使用
友元声明可以位于公有、私有或保护部分,其所在的位置无关紧要。因为它不属于类成员,但可以访问原始类的所有组件。类友元是一种自然用语,用于表示 一些关系。换句话说,需要根据实体之间的自然关系来确定是否使用友元。
1
友元成员函数
友元类中的某些方法并不需要作为友元,确实可以选择仅让特定的类城城欲成为另一个类的友元,而不必让整个类成为友元,但这样做稍微有点麻烦,必须小心 排列各种声明和定义的顺序。例如
1
2
3
4
5
class Tv
{
friend void Remote::set_chan(Tv & t, int c);
...
}
Tv 要知道 Remote 则 Remote 要在 Tv 前声明或定义,而 set_chan() 提到了 Tv ,那么 Tv 又要在 Remote 之前,这样就形成了循环依赖。为了避开这种 循坏依赖的方法是,使用前向声明。
1
解决方案
1
2
3
4
5
6
7
8
9
10
// 正确方案
class Tv; // forward declaration
class Remote {...}
calss Tv {...}
// 错误方案
class Remote; // forward declaration
class Tv {...}
class Remote {...}
1
2
第二个方案不行的原因是:
不符合使用之前必须先声明或定义的原则。
相互友元
这个更加要注意声明或定义的顺序了,也必须遵循“使用之前必须事先声明或定义”的原则。例如:Tv 和 Remote 的相互友元关系
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
class Tv
{
friend class Remote;
// Remote 是 Tv 的友元
public:
void buzz (Remote & r);
// 可以盛勇前向声明,
// 不过这里还没有定义,编译器不会检查类型
...
};
class Remote
{
friend class Tv;
// 相互友元
public:
void Bool volup(Tv & t) { t_volup(); }
...
};
inline void Tv::buzz(Remote & r)
{
...
}
共同的友元
需要使用友元的另一种情况是,函数需要访问两个雷的私有数据。从逻辑上看,这样的函数应是每个类的成员函数,但这是不可能的。它可以是一个类的成员。 同时是另一个类的友元,但有时将函数作为两个雷的友元更合理。
由于友元定义时是没有限定符的,既然是共同友元则应是同一个函数。
1
例子如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
class Analyzer; // forward declaration
class Probe
{
friend void sync(Analyzer & a, const Probe & p); // sync a to p
friend void sync(Probe & p, const Analyzer & a); // sync p to a
...
};
class Analyzer
{
friend void sync(Analyzer & a, const Probe & p); // sync a to p
friend void sync(Probe & p, const Analyzer & a); // sync p to a
}
inline void sync(Analyzer & a, const Probe & p)
{
...
}
inline void sync(Probe & p, const Analyzer & a)
{
...
}
嵌套类
在 C++ 中,可以将类声明放在另一个类中(可以参考结构体同样的做法)。在另一个类中声明的类被称为潜逃类,它通过提供新的类型类作用域来避免名称混乱。包含类的成员函数可以创建和使用被嵌套类的对象;而仅当声明位于公有部分 ,才能在包含类的外面使用嵌套类,而且必须使用作用域解析运算符。
对垒进行嵌套与包含并不同,包含意味着将类对象作为另一个类的成员,而对垒进行嵌套不创建类成员,而是定义了一种类型,该类型仅在包含嵌套类声明的类 中有效。
1
2
3
说白了,嵌套类就像二级目录之于一级目录
嵌套类和普通类一样只是要使用两次作用域解析运算符来提取而已
模板也可以嵌套(模板嵌套普通类,嵌套模板类,类嵌套模板)