docker 在开发、测试、部署和微服务治理、PaaS(平台即服务)以及云原生或云计算等领域已举足轻重。本文将简要探讨 一下 docker,主要从使用角度(而非源代码角度)的各个层面呈现其功能的强大和设计上的魅力。
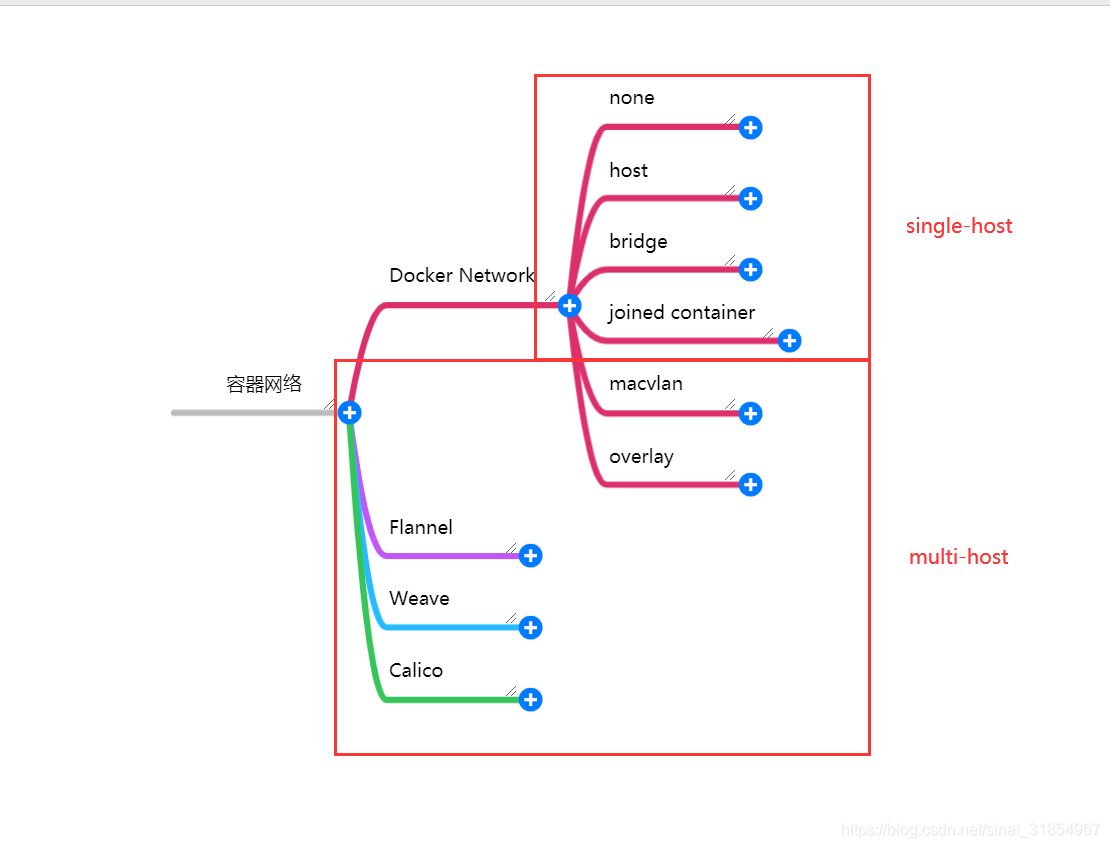
远观 docker
docker 在 LInux 系统实现的框架如下图:
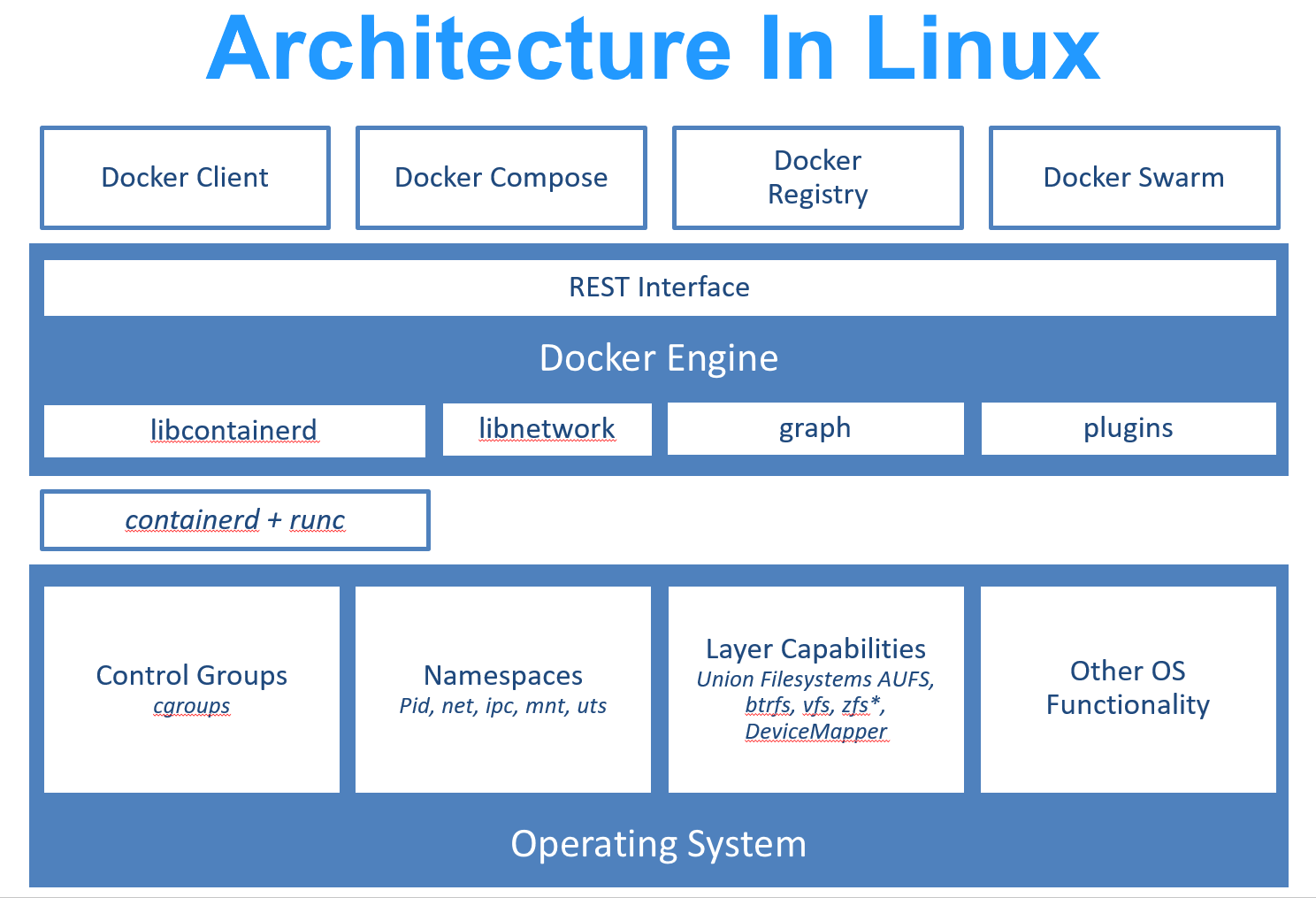
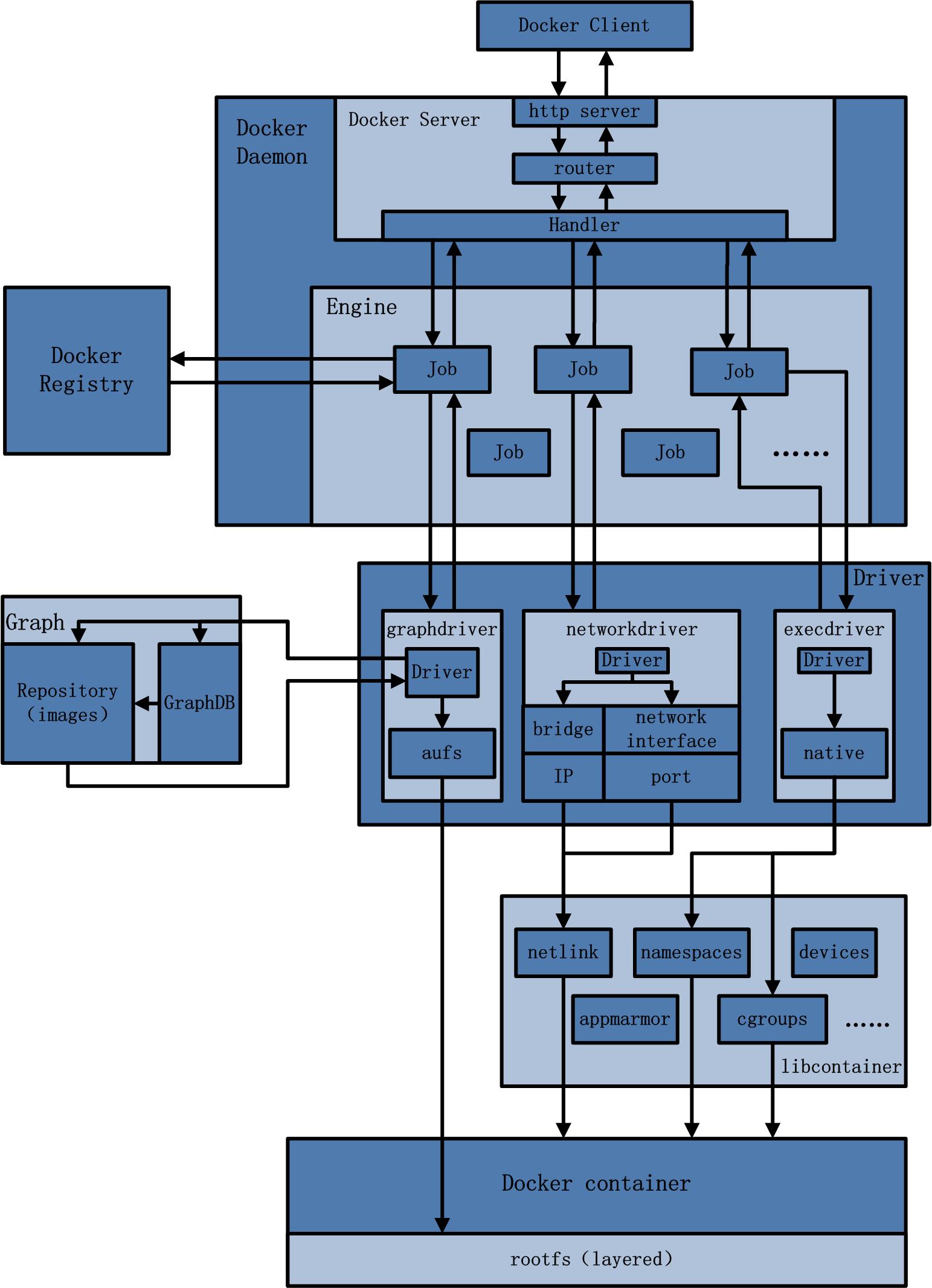
各个部分简单说明如下:
- Docker Client:是和Docker Daemon建立通信的客户端。用户使用的可执行文件为docker(类似可执行脚本的命令),docker命令后接参数的形式来实现一个完整的请求命令
- docker daemon:后台守护进程
- Docker Server:相当于C/S架构的服务端。功能为接受并调度分发Docker Client发送的请求。接受请求后,Server通过路由(Router)与分发调度,找到相应的Handler来执行请求
- Job:一个Job可以认为是Docker架构中Engine内部最基本的工作执行单元。Docker可以做的每一项工作,都可以抽象为一个job
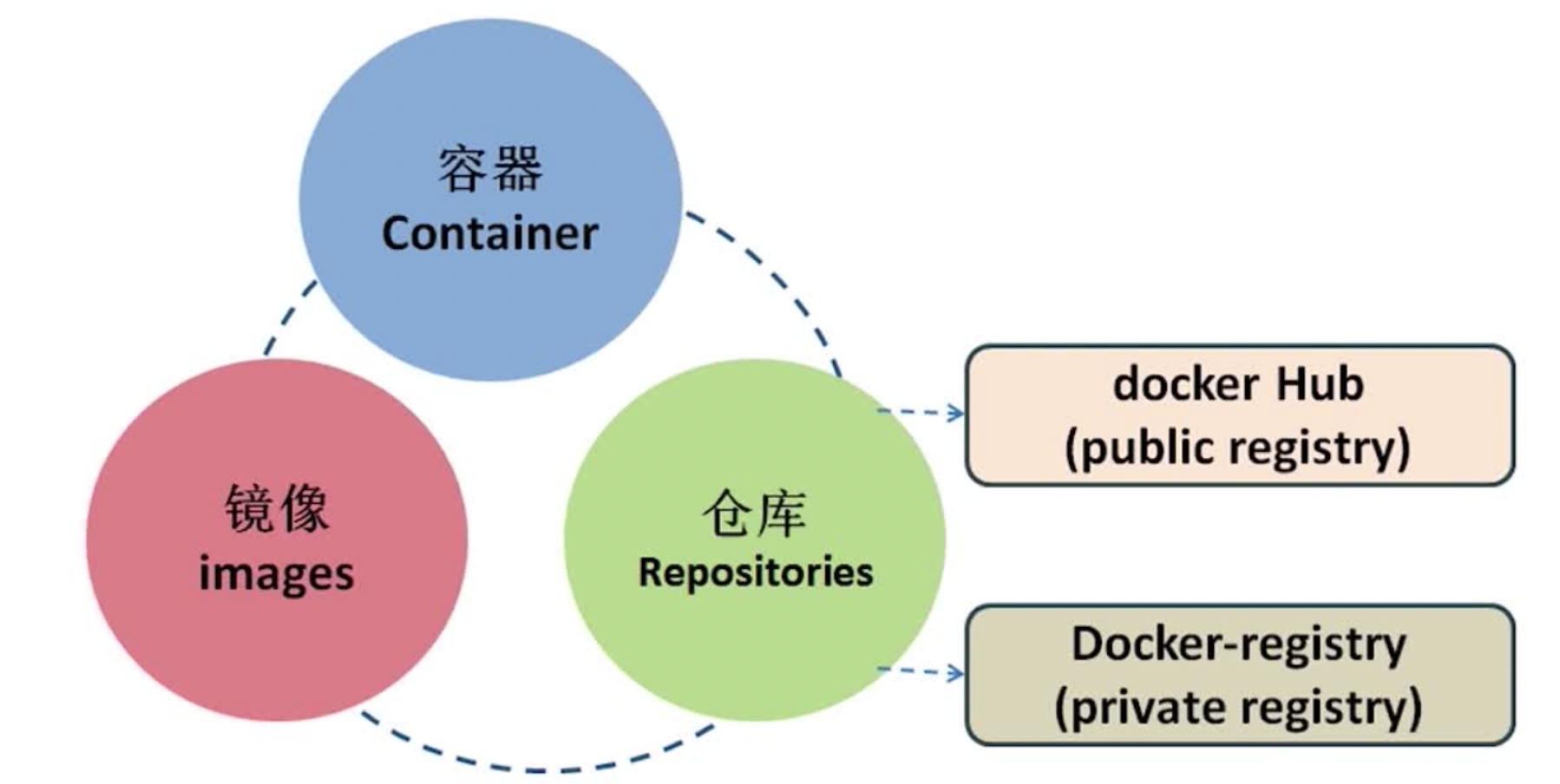
- Repository
- 已下载镜像的保管者(包括下载镜像和dockerfile构建的镜像)。
- 一个repository表示某类镜像的仓库(例如Ubuntu),同一个repository内的镜像用tag来区分(表示同一类镜像的不同标签或版本)。一个registry包含多个repository,一个repository包含同类型的多个image。
- 镜像的存储类型有aufs,devicemapper,Btrfs,Vfs等。其中centos系统使用devicemapper的存储类型。
- 同时在Graph的本地目录中,关于每一个的容器镜像,具体存储的信息有:该容器镜像的元数据,容器镜像的大小信息,以及该容器镜像所代表的具体rootfs。
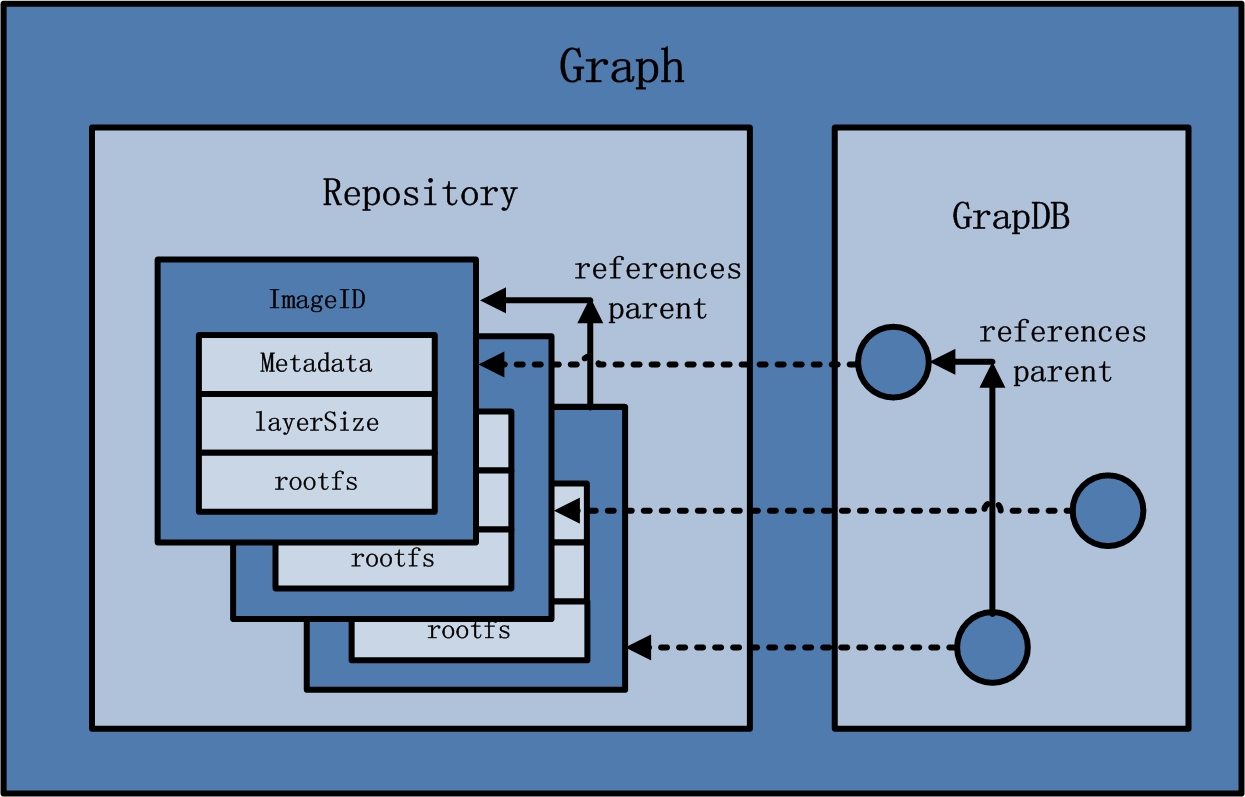
- GraphDB
- 已下载容器镜像之间关系的记录者。
- GraphDB是一个构建在SQLite之上的小型图数据库,实现了节点的命名以及节点之间关联关系的记录
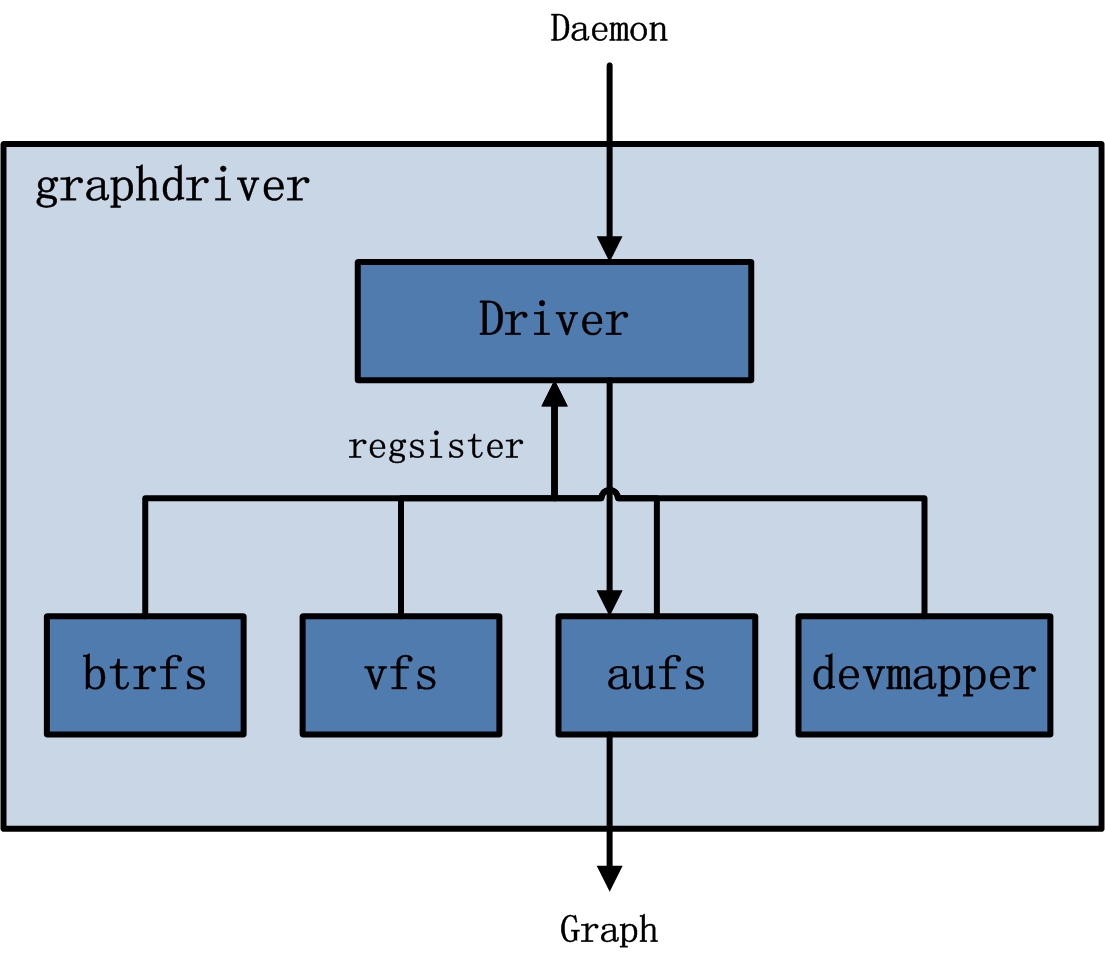
- graphdriver:主要用于完成容器镜像的管理,包括存储与获取。
- 存储:docker pull下载的镜像由graphdriver存储到本地的指定目录(Graph中)。
- 获取:docker run(create)用镜像来创建容器的时候由graphdriver到本地Graph中获取镜像。
- execdriver:作为Docker容器的执行驱动,负责创建容器运行命名空间,负责容器资源使用的统计与限制,负责容器内部进程的真正运行等。现在execdriver默认使用native驱动,不依赖于LXC
- libcontainer:是Docker架构中一个使用Go语言设计实现的库,设计初衷是希望该库可以不依靠任何依赖,直接访问内核中与容器相关的API
- Docker 容器就是 Docker 镜像的运行实例
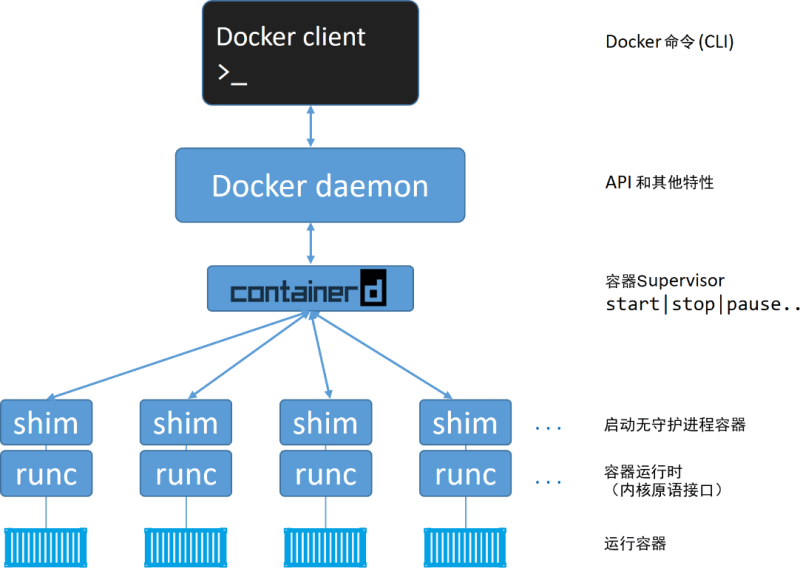
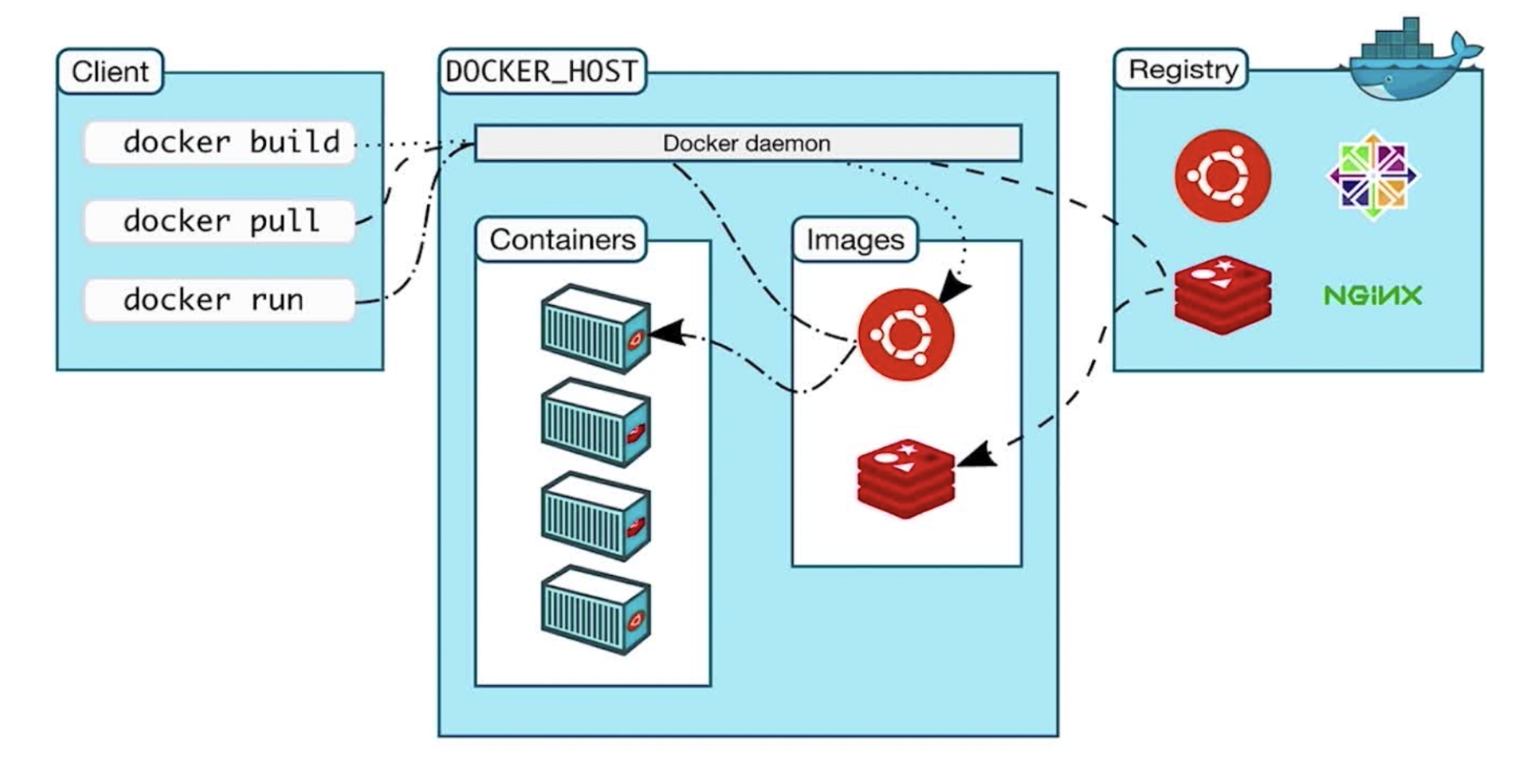
docker 命令图解
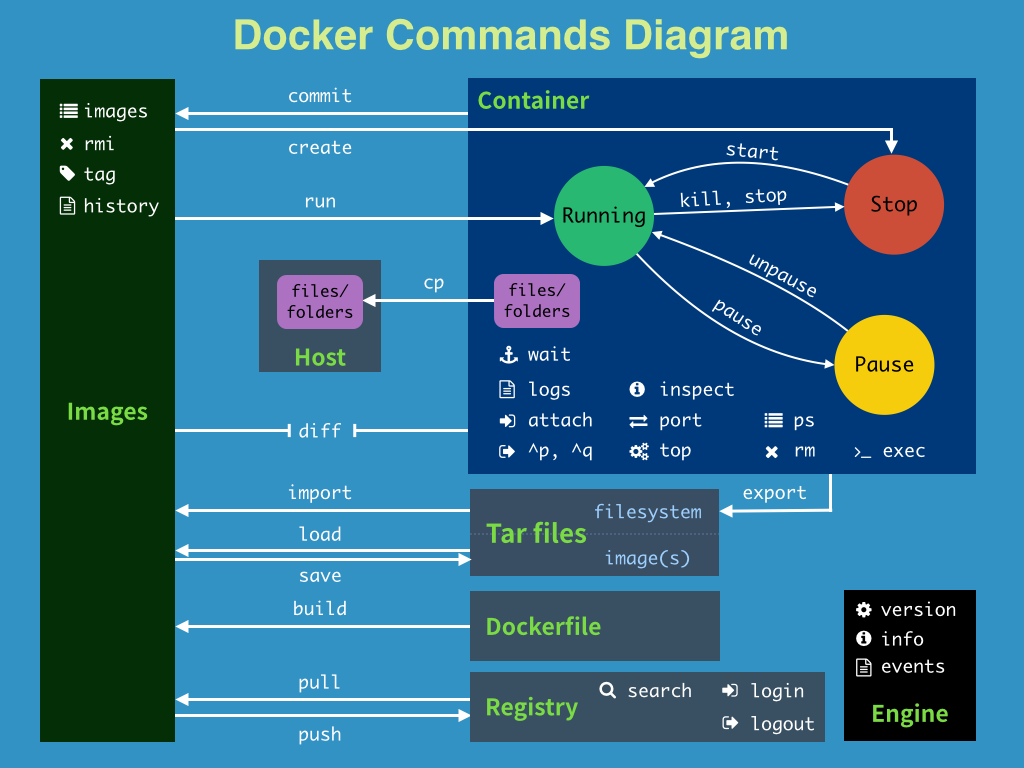
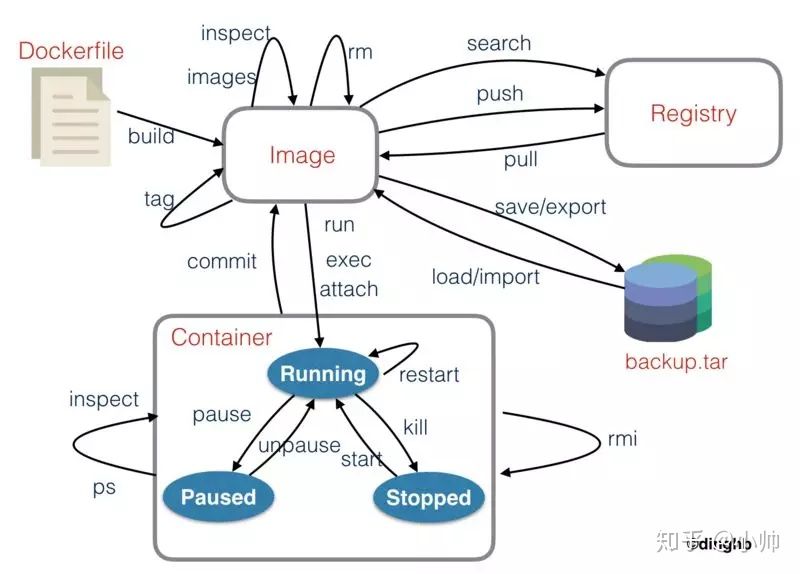
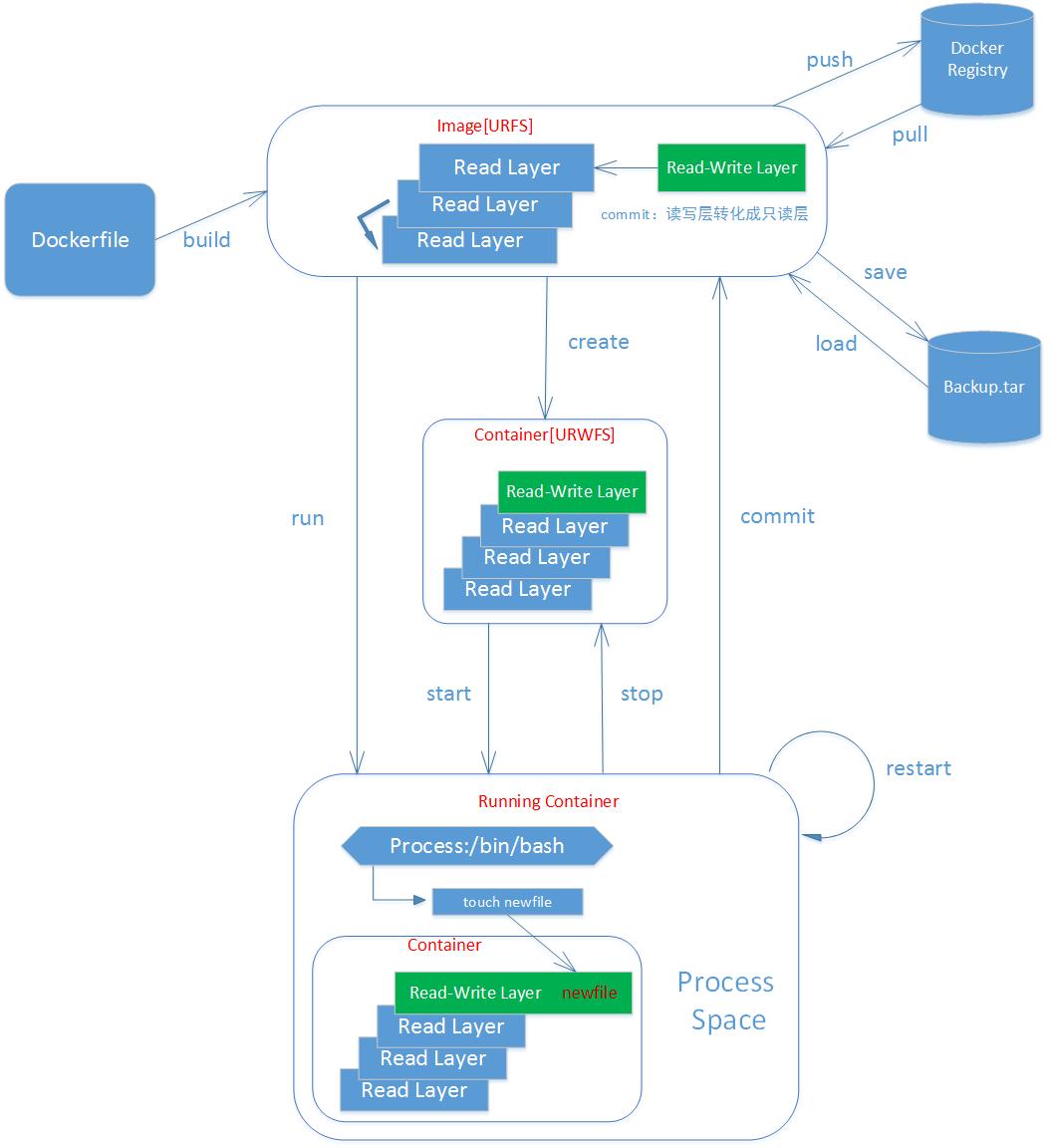
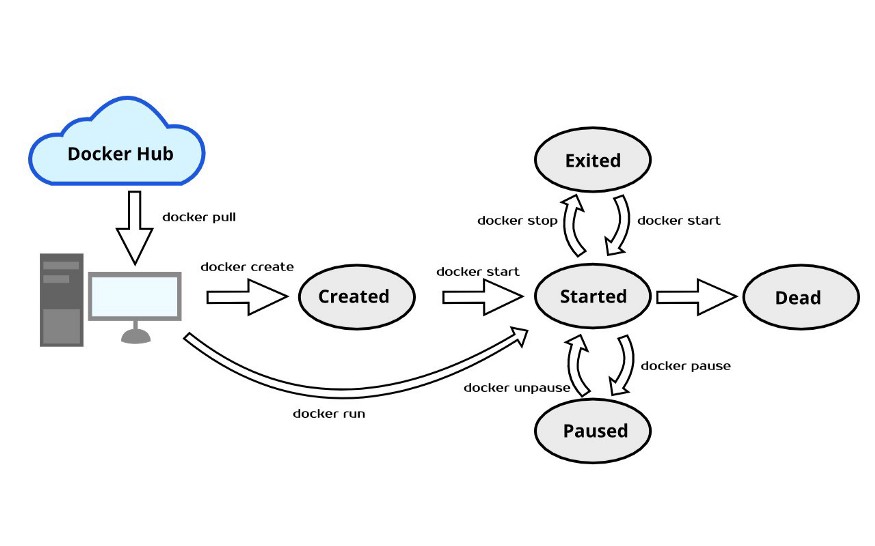
docker 生命周期
docker 生命周期 是指容器所处的状态 ,容器本质上是Host宿主机的进程,操作系统对于进程的管理是基于进程的状态切换的,进程从创建到销毁可能经过的路径图可以称之为“生命周期”。
docker 部署开发流程
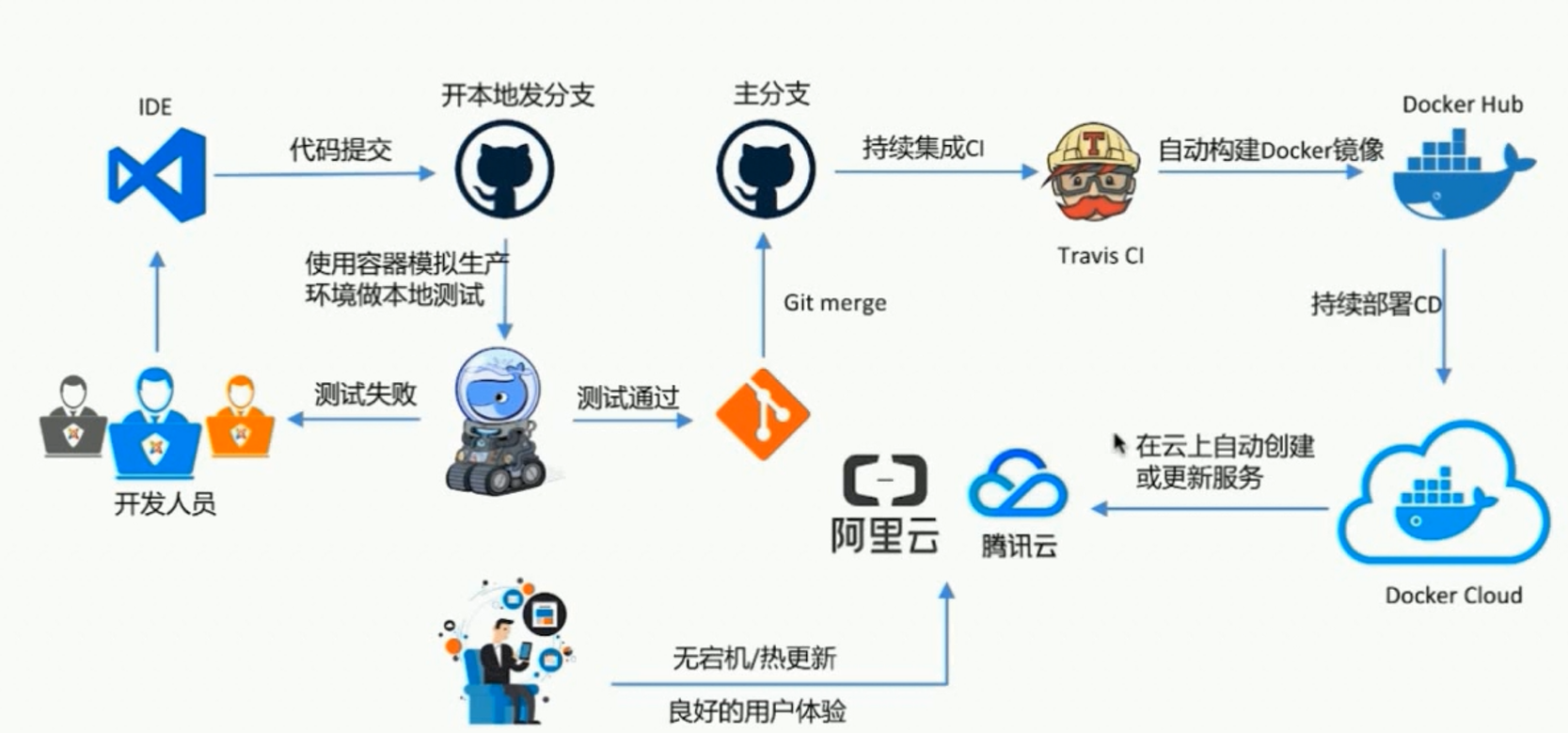
docker 容器集群编排工具
DockerFile
Dockerfile 是一个文本文件,其内包含了一条条的指令(Instruction),每一条指令构建一层,执行结束后,commit 这一层的修改,构成新的镜像。 因此每一条指令的内容,就是描述该层应当如何构建。 有了 Dockerfile,当我们需要定制自己额外的需求时,只需在 Dockerfile 上添加或者修改指令,重新生成 image 即可,省去了敲命令的麻烦。 有了该文件,可以通过 build 命令来构建镜像:docker build -f /path/to/a/Dockerfile .
Dockerfile 中每一个指令都会建立一层,RUN 也不例外。每一个 RUN 的行为,都会新建立一层,在其上执行这些命令,执行结束后,commit 这一层的修改,构成新的镜像
1
DockerFile 样例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
# This my first nginx Dockerfile
# Version 1.0
# 这个变量在每个 FROM 中都生效
# 构建参数和 ENV 的效果一样,都是设置环境变量。
# 所不同的是,ARG 所设置的构建环境的环境变量,在将来容器运行时是不会存在这些环境变量的
ARG DOCKER_BASE_IMAG=centos
# Base images 基础镜像
FROM ${DOCKER_BASE_IMAG}:7.7.1908
#MAINTAINER 维护者信息
MAINTAINER someone
#ENV 设置环境变量
#无论是后面的其它指令,如 RUN,还是运行时的应用,都可以直接使用这里定义的环境变量。
ENV PATH /usr/local/nginx/sbin:$PATH
#ADD 文件放在当前目录下,拷过去会自动解压
ADD nginx-1.8.0.tar.gz /usr/local/
ADD epel-release-latest-7.noarch.rpm /usr/local/
# 所有的文件复制均使用 COPY 指令,仅在需要自动解压缩的场合使用 ADD
COPY package.json /usr/src/app/
# 这里的 /data 目录就会在运行时自动挂载为匿名卷,任何向 /data 中写入的信息都不会记录进容器存储层,从而保证了容器存储层的无状态化。
# 当然,运行时可以覆盖这个挂载设置。比如:
# docker run -d -v mydata:/data -t ny_nginx
# 以上在这行命令中,就使用了 mydata 这个命名卷挂载到了 /data 这个位置,替代了 Dockerfile 中定义的匿名卷的挂载配置
VOLUME /data
#RUN 执行以下命令
# RUN rpm -ivh /usr/local/epel-release-latest-7.noarch.rpm
# RUN yum install -y wget lftp gcc gcc-c++ make openssl-devel pcre-devel pcre && yum clean all
# RUN useradd -s /sbin/nologin -M www
# 上面的这种写法,创建了 3 层镜像。这是完全没有意义的,而且很多运行时不需要的东西,都被装进了镜像里
# 推荐下面的写法
RUN buildDeps='wget lftp gcc gcc-c++ make openssl-devel pcre-devel pcre' \
&& rpm -ivh /usr/local/epel-release-latest-7.noarch.rpm \
&& yum install -y $buildDeps \
&& useradd -s /sbin/nologin -M www
#WORKDIR 相当于cd
WORKDIR /usr/local/nginx-1.8.0
RUN ./configure --prefix=/usr/local/nginx --user=www --group=www --with-http_ssl_module --with-pcre && make && make install
RUN echo "daemon off;" >> /etc/nginx.conf
# USER 指令和 WORKDIR 相似,都是改变环境状态并影响以后的层。WORKDIR 是改变工作目录,
# USER 则是改变之后层的执行 RUN, CMD 以及 ENTRYPOINT 这类命令的身份。
# 当然,和 WORKDIR 一样,USER 只是帮助你切换到指定用户而已,这个用户必须是事先建立好的,否则无法切换
RUN groupadd -r nginx_user && useradd -r -g nginx_user nginx_user
USER nginx_user
#EXPOSE 映射端口
EXPOSE 80/tcp 8080 123456
#CMD 运行以下命令
# 比如在终端执行命令 docker run my_nginx
# 则会执行下面的 CMD 命令
# 与 CMD 类似的还有 ENTRYPOINT,不过后者支持终端 docker run 命令追加参数
# 如 docker run my_nginx -v
# ENTRYPOINT ["nginx"]
# 以上两个命令相当于 CMD ["nginx", "-v"]
CMD ["nginx"]
docker compose
前面提到的 dockerFile 可以构建单个镜像,当然单个镜像中可以打包多个应用(比如mysql、redis)。但不建议这么做,因为会导致 这个镜像非常大,而且东西多了,重用它的额外代价也比较高。同时对于集群应用(比如mysql,redis 集群)是无法通过单个镜像完成的。 那对于需要同时启动众多镜像的场景,你可以有以下方案:
- 在命令行中敲命令逐个启动容器,直到所需的容器全部启动完毕
- 把要执行的所有命令写在一个shell脚本中,执行这个脚本即可
- 使用 docker compose 等 docker 编排工具
Docker Compose 是一个用来定义和运行复杂应用的Docker工具。一个使用Docker容器的应用,通常由多个容器组成。使用Docker Compose 不再需要使用shell脚本来启动容器。 Compose 通过一个配置文件来管理多个Docker容器,在配置文件中,所有的容器通过services来定义,然后使用docker-compose脚本来启动,停止和重启应用, 和应用中的服务以及所有依赖服务的容器,非常适合组合使用多个容器进行开发的场景。
Docker-Compose是一个容器编排工具。通过一个.yml或.yaml文件,将所有的容器的部署方法、文件映射、容器端口映射等情况写在一个配置文件里, 执行 docker compose up 命令就像执行脚本一样,一个一个的安装并部署容器。compose 支持的配置项详见官方文档, 下面只给出一个简单的实例。
1
常用的命令有:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 当配置文件修改后或者对于一个新的配置文件最好逐个执行以下命令
# 删除上次构建的容器
docker compose down
# 重新构建镜像 --force-rm 删除构建过程中的临时容器。
docker compose build --force-rm
# 运行容器
# 对于没有变动过的配置文件,之前已经执行了这里的所有命令的,之后启动只需要执行这个即可
docker compose up -d
# 其他命令可以使用 help
docker compose -help
1
配置文件样例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
version: '3'
networks:
dev:
# 系列服务组
services:
####################### mongodb ######################
# mongo:
# container_name: mongo
# image: mongo
# restart: always
# environment:
# MONGO_INITDB_ROOT_USERNAME: root
# MONGO_INITDB_ROOT_PASSWORD: 123456
# networks:
# - dev
# ports:
# - 27017:27017
##################### kafka ######################
# 某个服务的配置
zookeeper:
image: wurstmeister/zookeeper
ports:
- "2181:2181"
networks:
- dev
kafka:
image: wurstmeister/kafka
depends_on: [ zookeeper ]
ports:
- "9092:9092"
environment:
KAFKA_ADVERTISED_HOST_NAME: 192.168.33.20
KAFKA_CREATE_TOPICS: "test:1:1"
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
volumes:
- ./data/kafka/docker.sock:/var/run/docker.sock
networks:
- dev
####################### etcd ########################
etcd:
container_name: etcd
image: bitnami/etcd:3
#image: quay.io/coreos/etcd:v3.3
restart: always
environment:
- ALLOW_NONE_AUTHENTICATION=yes
- ETCD_ADVERTISE_CLIENT_URLS=http://etcd:2379
networks:
- dev
ports:
- 2379:2379
- 2380:2380
####################### nsqdb ########################
# nsqlookupd:
# image: nsqio/nsq
# command: /nsqlookupd
# networks:
# - dev
# hostname: nsqlookupd
# ports:
# - "4161:4161"
# - "4160:4160"
# nsqd:
# image: nsqio/nsq
# command: /nsqd --lookupd-tcp-address=nsqlookupd:4160 -broadcast-address=192.168.33.20
# depends_on:
# - nsqlookupd
# hostname: nsqd
# networks:
# - dev
# ports:
# - "4151:4151"
# - "4150:4150"
# nsqadmin:
# image: nsqio/nsq
# command: /nsqadmin --lookupd-http-address=nsqlookupd:4161
# depends_on:
# - nsqlookupd
# hostname: nsqadmin
# ports:
# - "4171:4171"
# networks:
# - dev
####################### mysql5.7 ########################
mysql5.7:
container_name: mysql5.7
image: mysql:5.7
restart: always
command: --default-authentication-plugin=mysql_native_password --character-set-server=utf8mb4 --collation-server=utf8mb4_unicode_ci
environment:
- MYSQL_ROOT_PASSWORD=123456
- LANG=C.UTF-8
networks:
- dev
volumes:
- ./data/mysql:/var/lib/mysql ##自建目录
ports:
- 3306:3306
phpmyadmin:
image: phpmyadmin
container_name: phpmyadmin
environment:
- PMA_ARBITRARY=1
restart: always
links:
- mysql5.7
ports:
- 8090:80
volumes:
- /sessions
networks:
- dev
######################## redis ########################
redis:
image: bitnami/redis:latest
container_name: redis
restart: always
ports:
- 6379:6379
networks:
- dev
environment:
- ALLOW_EMPTY_PASSWORD=yes
volumes:
- ./redis.conf:/usr/local/etc/redis/redis.conf:rw
- ./data/redis:/data:rw ##自建目录
command:
/bin/bash -c "redis-server /usr/local/etc/redis/redis.conf"
######################## nginx ########################
# web:
# container_name: web
# image: nginx:latest
# restart: always
# volumes:
# - "./etc/nginx:/etc/nginx" ##自建目录
# - "./logs:/logs" ##自建目录
# ports:
# - 80:80
# - 443:443
# networks:
# - dev
#################################Microservices##############################
#
# service_user:
# container_name: service_user
# image: alpine:latest
# restart: always
# volumes:
# - "./bin/service_user:/service_user"
# - "./etc/service_user.yaml:/service_user.yaml"
# - "./logs:/logs"
# command: /service_user -f /service_user.json
# networks:
# - dev
# ports:
# - 8080:8080
compose 支持以下使用场景:
- 单服务单容器使用
- 多服务多容器依赖使用
- 多服务多容器独立使用
- 单服务多容器使用
Docker Desktop
Docker Desktop 官方口号“容器化和共享任何应用程序”,支持跨云、语言和框架的任意组合。 其包括开发者工具、Kubernetes 和与生产 Docker 引擎的版本同步。 你可以把它理解成对应命令行工具的图形界面软件,比较简便,这里不再详述。至于如何安装可参阅 官方文档
Docker Desktop 和 Desktop Enterprise 为开发人员提供了与生产集群一致的Docker 和 Kubernetes环境。 使用唯一能够提供可信且经过认证的端到端安全性的平台,在任何地方构建和运行相同的应用程序。 对于开发人员和相关测试人员来说,不需要对 Docker 或 Kubernetes 有着非常深的理解。 Docker 可以在几分钟内轻松启动和运行,快速编码、测试和协作,同时确保开发和生产之间的一致性。
Portainer
Portainer是一个可视化的容器镜像的图形管理工具,利用Portainer可以轻松构建,管理和维护Docker环境(如docker的containers、images、volumes、networks等等)。 而且完全免费,基于容器化的安装方式,方便高效部署。 它由一个可以运行在任何docker引擎上的容器组成。Portainer提供管理docker的
非常值得推荐的是它可以图形化的管理docker和本地的k8s,并且通过agent的方式发现不同主机的docker列表和k8s集群,并可以通过api去管理相关服务。 具体使用方法和场景可参阅官方文档
适合使用Docker或Docker Swarm,没有容器管理工具的场景,如开发环境、测试环境和暂时不想使用k8s的场景的生产环境。可以把它当做轻量级的微服务部署管理系统。
swarm
Docker 的单节点引擎工具 Docker Compose,它能够在单一节点上管理和编排多个容器,当我们的服务和容器数量较小时可以使用 Docker Compose 来管理容器。
然而随着我们的业务规模越来越大,我们的容器规模也逐渐增大时,数量庞大的容器管理将给我们带来许多挑战。 Docker 官方为了解决多容器管理的问题推出了 Docker Swarm ,我们可以用它来管理规模更大的容器集群。 如何使用可以通过命令 docker swarm --help 得到对应帮助。
Docker Swarm 是一个 Dockerized 化的分布式应用程序的本地集群。具体来说,Docker Swarm 支持用户创建可运行 Docker Daemon 的主机资源池, 然后在资源池中运行 Docker 容器。Docker Swarm 可以管理工作负载并维护集群状态。
除了资源优化,Docker Swarm 可以保证应用的高可用性和容错性。Docker Swarm 会不断的检查 Docker Daemon 所在主机的健康状态。 当某个主机不可用时,Swarm 就会将容器迁移到新的主机上。
Docker Swarm 的亮点之一是它可以在应用的生命周期内扩展,也就是说当应用从一个主机扩展到 2 个、20 个或者 200 个的时候,用户可以保证接口的一致性。 具体操作可以参考以下文章
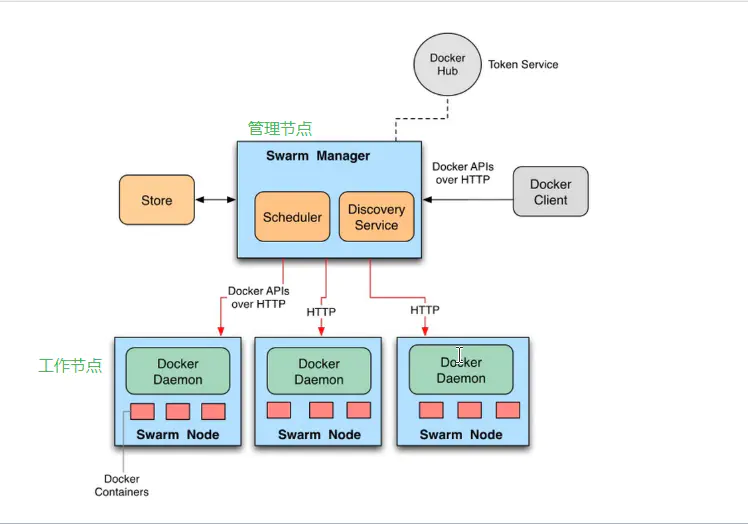
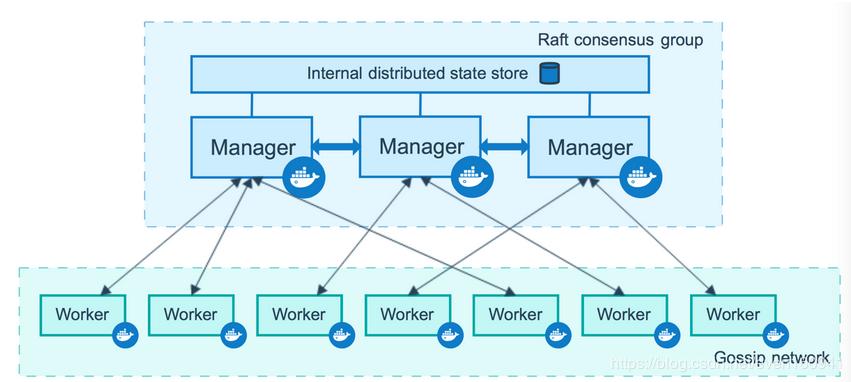
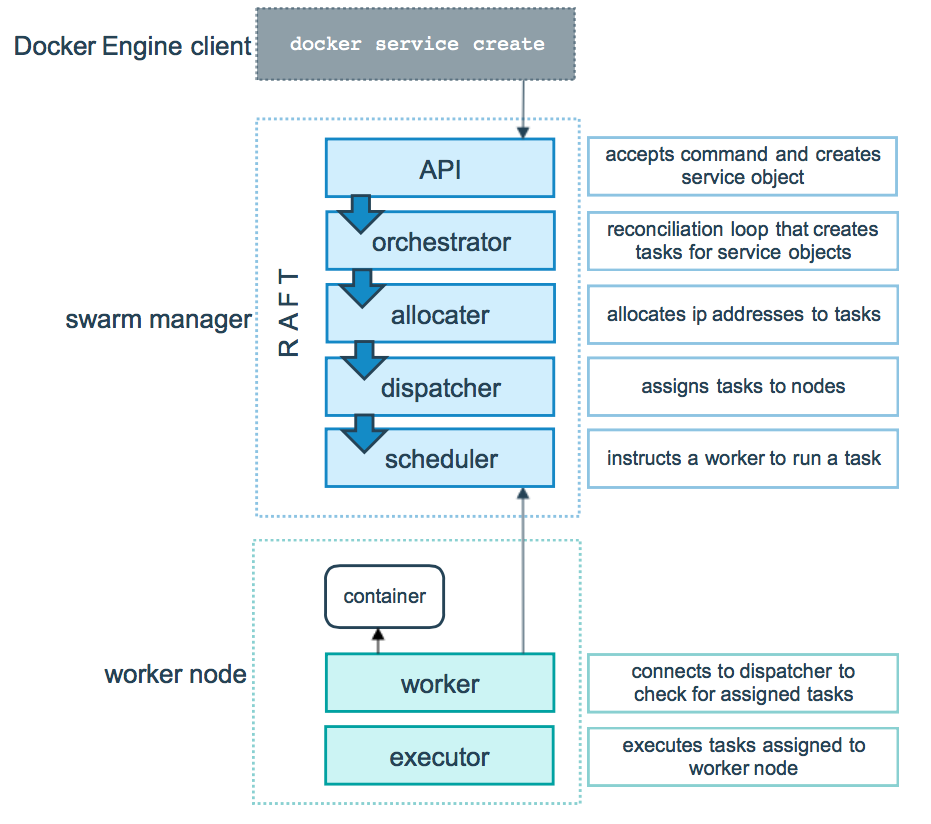
kubernetes
当微服务数量众多或者依赖的集群化组件过多时,如果用 Docker Compose 配置文件或者脚本来管理,会让人崩溃而且 很难维护,只要部署完了之后,没人敢去动了。因此,落地庞大的微服务架构是绕不开类似k8s的部署和运行动态管理平台的。
1
k8s 是什么:
- Kubernetes 是舵手的意思,我们把 Docker 比喻成一个个集装箱,而 Kubernetes 正是运输这些集装箱的舵手。
- Kubernetes 是一个可移植的,可扩展的开源平台,用于管理容器化的工作负载和服务,可促进声明式配置和自动化。
Kubernetes 目前已经支持在多种环境下安装,我们可以在公有云,私有云,甚至裸金属中安装 Kubernetes。 minikube 是官方提供的一个快速搭建本地 Kubernetes 集群的工具,主要用于本地开发和调试。详细介绍和使用指南可参阅 官方文档
1
k8s 至少有以下特点:
- 自动装箱,水平扩展,自我修复
- 服务发现和负载均衡与伸缩(Ingress和kube-proxy)
- 自动灰度发布(默认滚动发布模式)和回滚
- 集中化配置管理和密钥管理(ConfigMap和Secrets)
- 存储编排(Volume)
- 任务批处理运行
架构简介
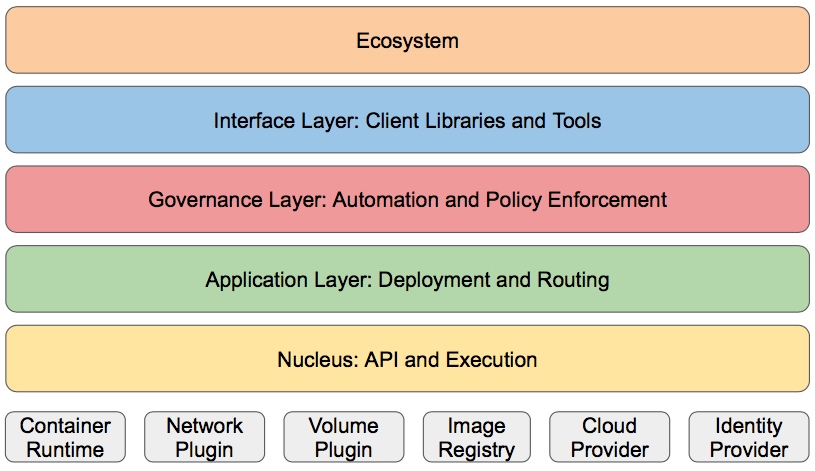
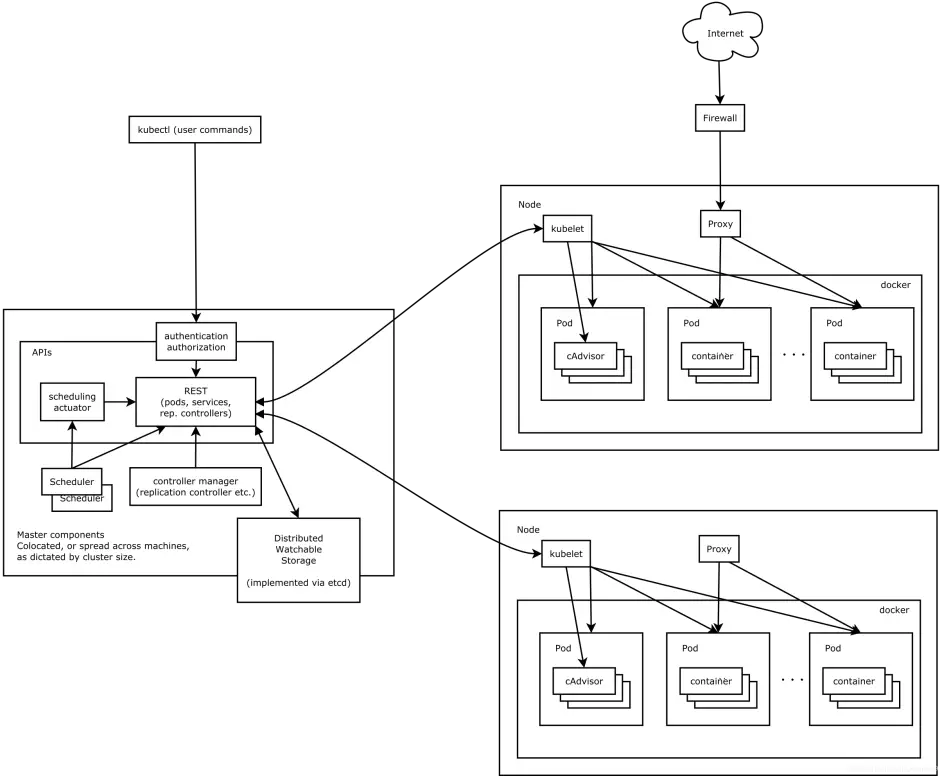
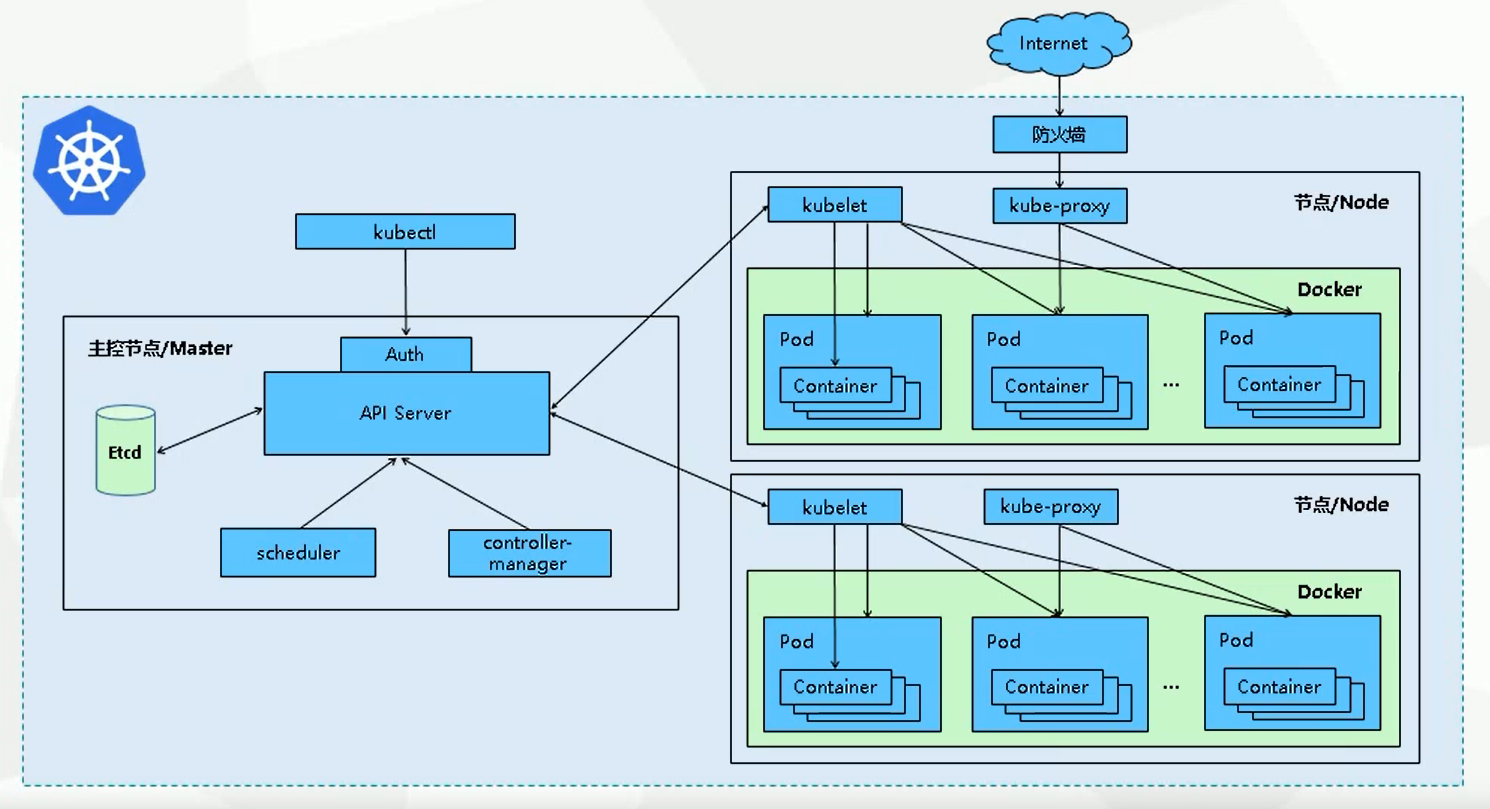
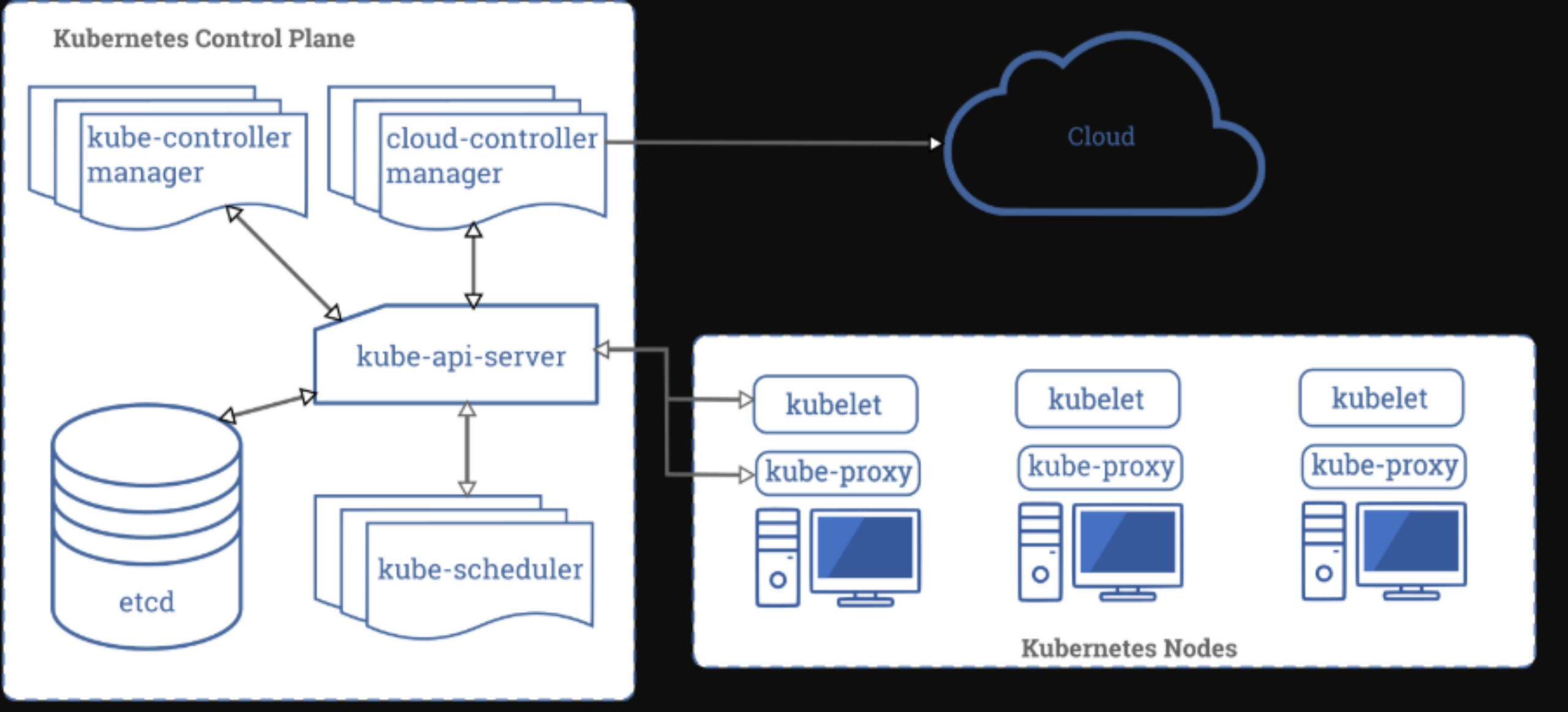
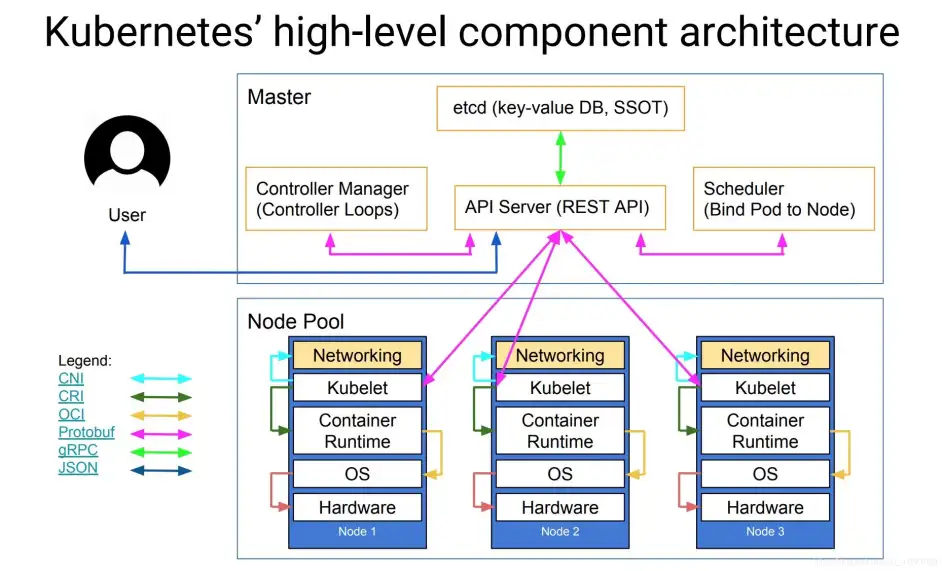
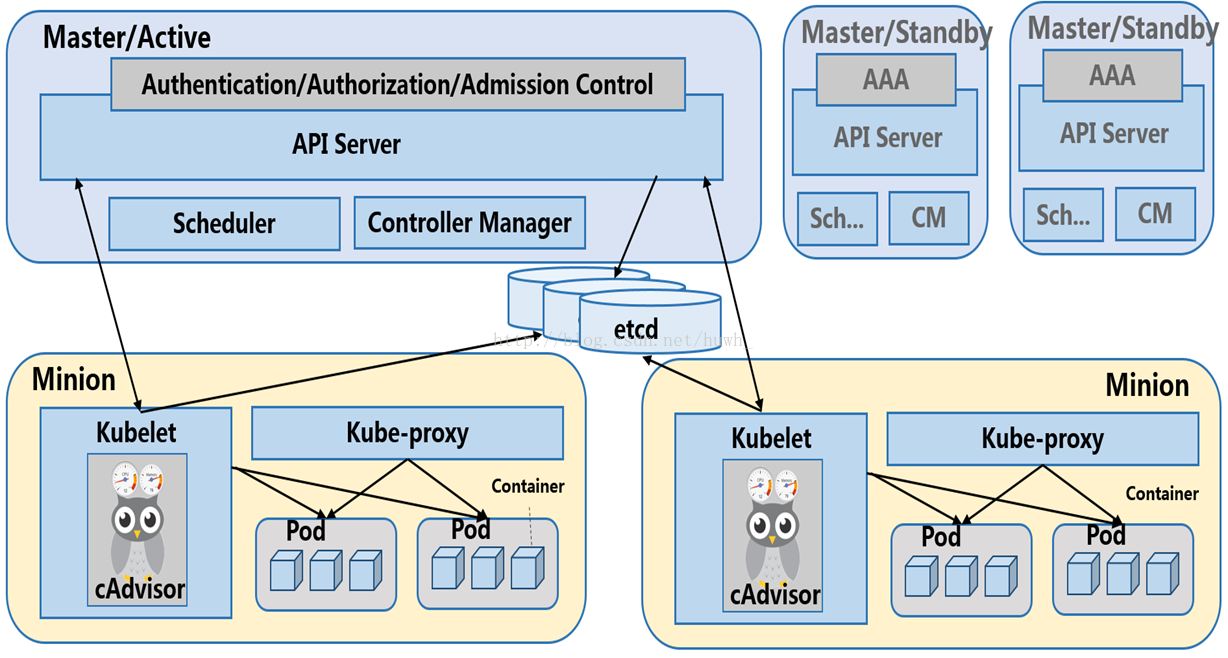
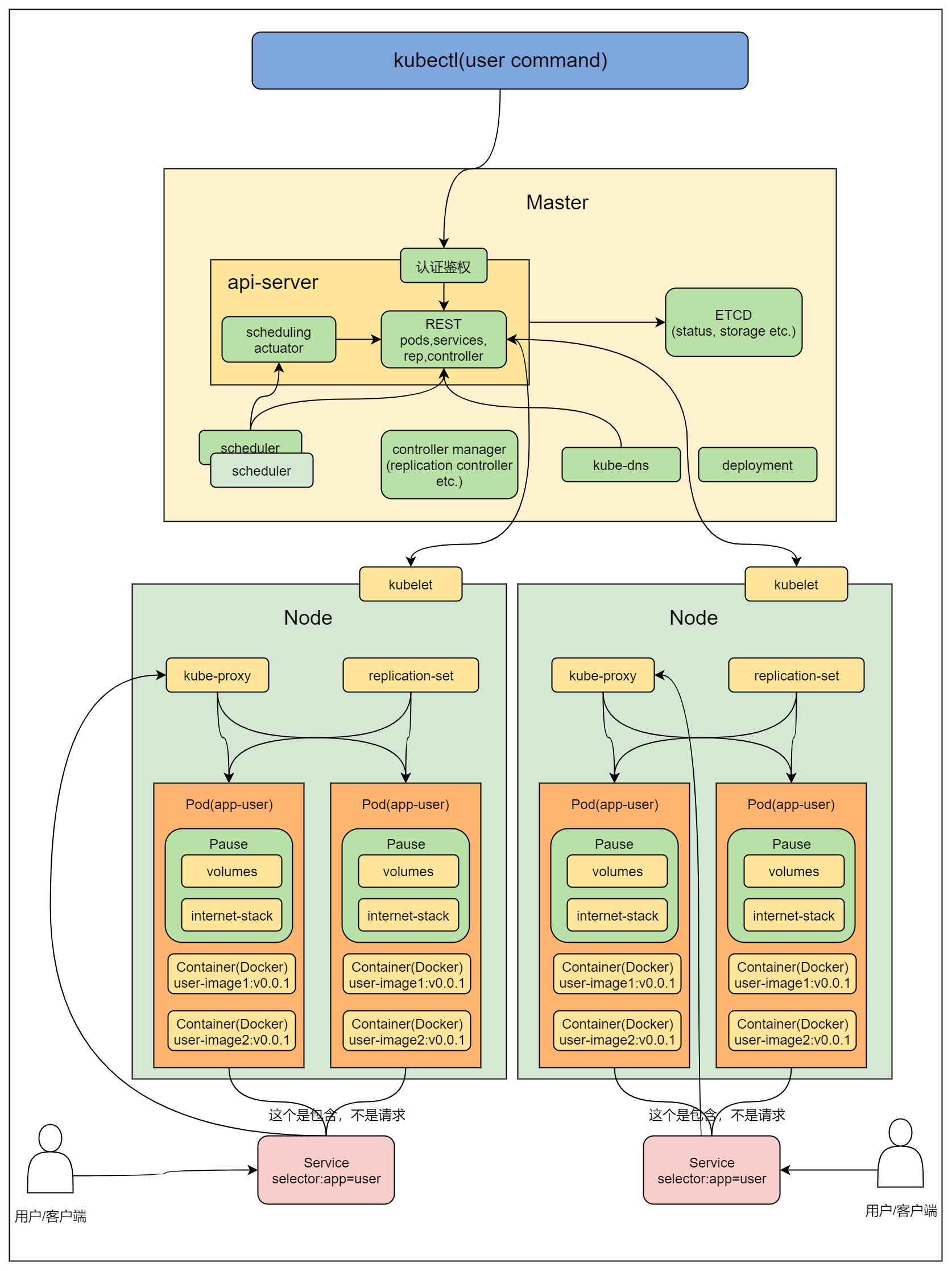
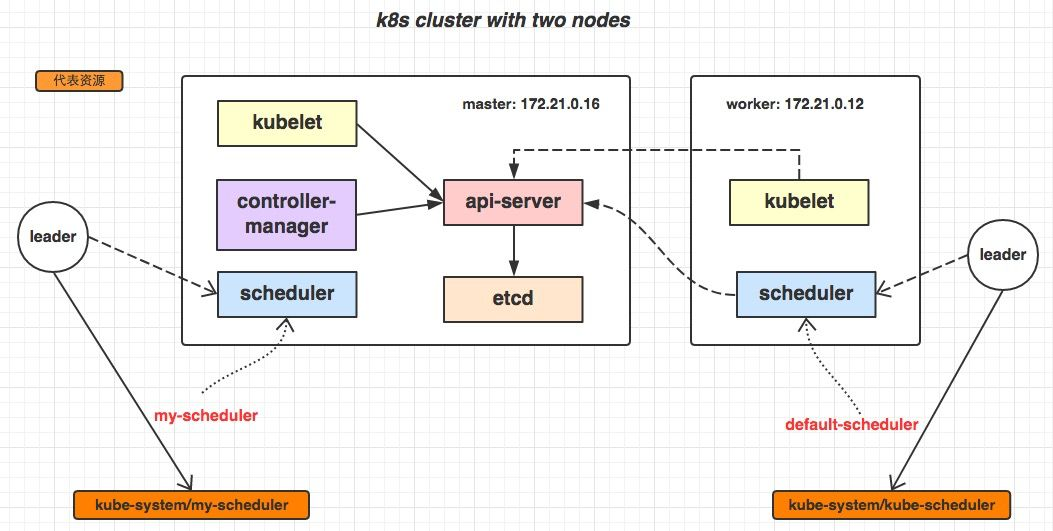
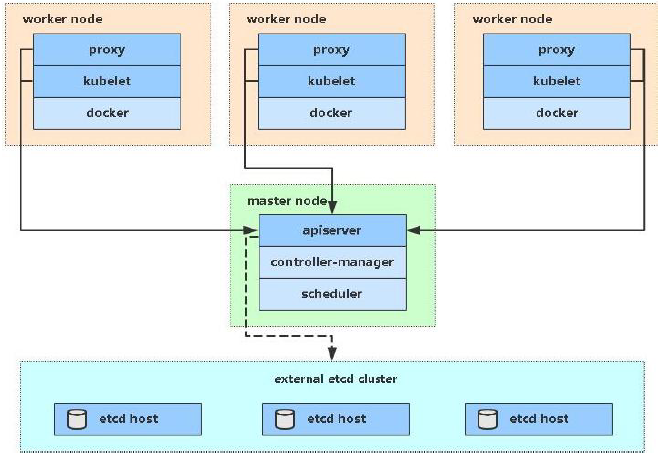
API server
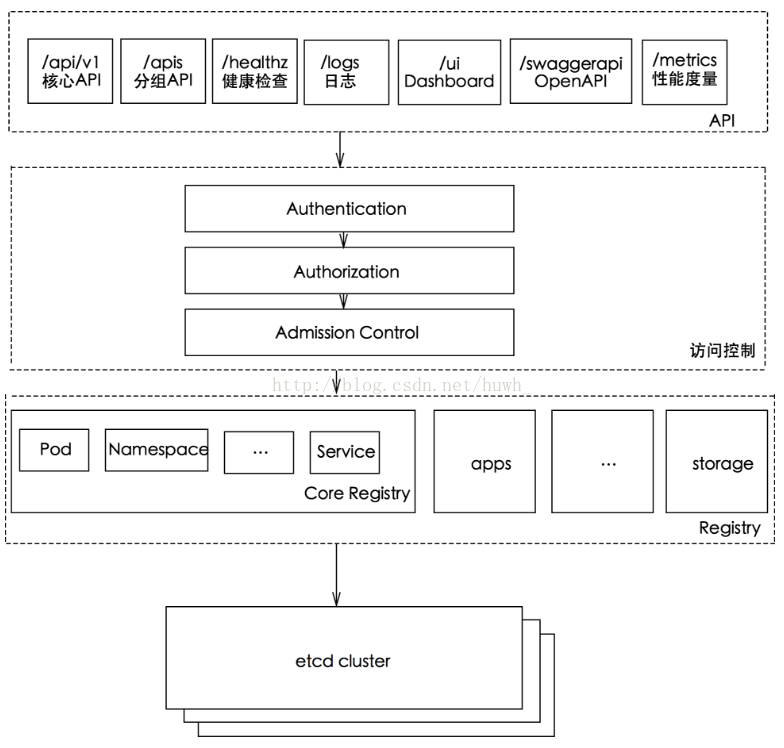
API Server 扮演着通信枢纽的位置。API Server 不仅负责和 etcd 交互(其他组件不会直接操作 etcd,只有 API Server 这么做), 并且对外提供统一的API调用入口, 所有的交互都是以 API Server 为核心的。API Server 提供了以下的功能:
- 集群控制的入口:提供了 RESTful API 接口的关键服务进程,是 Kubernetes 里所有资源的增删改查等操作的唯一入口。 创建一个资源对象如Deployment、Service、RC、ConfigMap等,都是要通过API Server的。通过API Server,我们就可以往Etcd中写入数据。Etcd中存储着集群的各种数据。
- 资源配额控制的入口: Kubernetes 可以从各个层级对资源进行配额控制。如容器的CPU使用量、Pod的CPU使用量、namespace的资源数量等。这也是通过API Server进行配置的。将这些资源配额情况写入到Etcd中
- 集群内部各个模块之间通信的枢纽:所有模块之前并不会之间互相调用,而是通过和 API Server 打交道来完成自己那部分的工作。
Controller Manager
Controller Manager作用是通过API Server监控Etcd中的节点信息,定时通过API Server读取Etcd中的节点信息,监控到异常就会自动进行某种操作。
负责管理集群各种资源,保证资源处于预期的状态。Controller Manager由多种controller组成, 包括node controller、replication controller、endpoints controller、namespace controller、serviceaccounts controller等。 由控制器完成的主要功能主要包括生命周期功能和API业务逻辑,具体如下:生命周期功能:包括Namespace创建和生命周期、Event垃圾回收、 Pod终止相关的垃圾回收、级联垃圾回收及Node垃圾回收等。API业务逻辑:例如,由ReplicaSet执行的Pod扩展等。
1
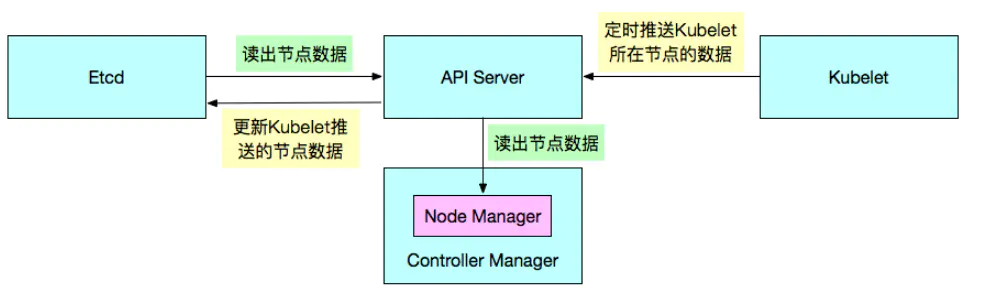
Node Controller:
node controller 通过API Server监控Etcd中存储的关于节点的各类信息,会定时通过API Server读取这些节点的信息,这些节点信息是由kubelet定时推给API Server的,由API Server写入到Etcd中。
这些节点信息包括:节点健康状况、节点资源、节点名称、节点地址信息、操作系统版本、Docker版本、kubelet版本等。监控到节点信息若有异常情况,则会对节点进行某种操作,如节点状态变为故障状态,则删除节点与节点相关的Pod等资源的信息。
1
Namespace Controller:
用户是可以通过API Server创建新的namespace并保存在Etcd中的。Namespace Controller会定时通过API Server读取这些Namespace信息并做对应的对于Namespace的一些操作。
1
ResourceQuota Controller:
将期望的资源配额信息通过API Server写入到Etcd中。然后ResourceQuota Controller会定时的统计这些信息,在系统请求资源的时候就会读取这些统计信息,如果不合法就不给分配该资源,则创建行为会报错。
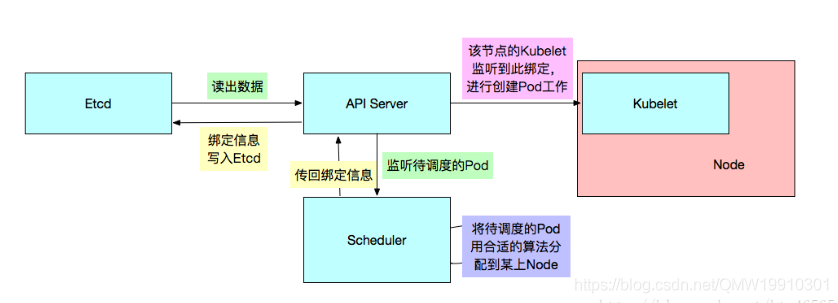
Scheduler
Kubernetes的调度器,负责 Pod 资源调度。Scheduler监听API Server,当需要创建新的Pod时。Scheduler负责选择该Pod与哪个Node进行绑定。将此绑定信息通过API Server写入到Etcd中。 若此时与Node A进行了绑定,那么A上的Kubelet就会从API Server上监听到此事件,那么该Kubelet(Kubelet除了监听API Server做相应的操作之外,还定时推送它所在节点的信息给API Server)就会做相应的创建工作。 此调度涉及到三个对象,待调度的Pod,可用的Node,调度算法。简单的说,就是使用某种调度算法为待调度的Pod找到合适的运行此Pod的Node。
Kubelet
Kubelet负责 Pod 对应的容器的创建,启动等任务,同时与Master节点密切协作。 每个Node节点上都会有一个Kubelet负责Master下发到该节点的具体任务,管理该节点上的Pod和容器。 而且会在创建之初向API Server注册自身的信息,定时汇报节点的信息。它还通过cAdvisor监控容器和节点资源。
- 节点管理:Kubelet在创建之初就会向API Server做自注册,然后会定时报告节点的信息给API Server写入到Etcd中。默认为10秒。
- Pod管理:Kubelet会监听API Server,如果发现对Pod有什么操作,它就会作出相应的动作。例如发现有Pod与本Node进行了绑定。 那么Kubelet就会创建相应的Pod且调用Docker Client下载image并运行container。
- 容器健康检查: 有三种方式对容器做健康检查。
- 在容器内部运行一个命令,如果该命令的退出状态码为0,则表明容器健康
- TCP检查
- HTTP检查
- cAdvisor资源监控:Kubelet通过cAdvisor对该节点的各类资源进行监控。如果集群需要这些监控到的资源信息,可以安装一个组件Heapster。 Heapster会进行集群级别的监控,它会通过Kubelet获取到所有节点的各种资源信息,然后通过带着关联标签的Pod分组这些信息。 如果再配合InfluxDB与Grafana,那么就成为一个完整的集群监控系统了。
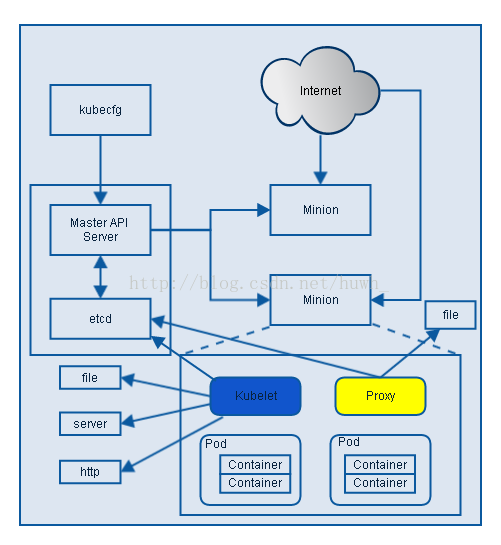
Kube-proxy
实现 Kubernetes Service 的通信与负载均衡机制的重要组件。 负责接收并转发请求。Kube-proxy的核心功能是将到Service的访问请求转发到后台的某个具体的Pod。 无论是通过ClusterIP+Port的方式,还是NodeIP+NodePort的方式访问Service,最终都会被节点的Iptables规则重定向到Kube-proxy监听服务代理端口, 该代理端口实际上就是SocketServer在本地随机打开的一个端口,SocketServer是Kube-proxy为每一个服务都会创建的“服务代理对象”的一部分。 当Kube-proxy监听到Service的访问请求后,它会找到最适合的Endpoints,然后将请求转发过去。具体的路由选择依据Round Robin算法及Service的Session会话保持这两个特性。
首先k8s 里所有资源都存在 etcd 中,各个组件通过 apiserver 的接口进行访问etcd来获取资源信息 kube-proxy 会作为 daemon(守护进程) 跑在每个节点上通过watch的方式监控着etcd中关于Pod的最新状态信息, 它一旦检查到一个Pod资源被删除了或新建或ip变化了等一系列变动,它就立即将这些变动,反应在iptables 或 ipvs规则中, 以便之后 再有请求发到service时,service可以通过ipvs最新的规则将请求的分发到pod上
Etcd
Etcd一种k-v存储仓库,可用于服务发现程序。在Kubernetes中就是用Etcd来存储各种k-v对象的。 所以我也认为Etcd是Kubernetes的一个重要组件。当我们无论是创建Deployment也好,还是创建Service也好,各种资源对象信息都是写在Etcd中了。 各个组件是通过API Server进行交流的,然而数据的来源是Etcd。所以维持Etcd的高可用是至关重要的。如果Etcd坏了,任何程序也无法正常运行了。
etcd在kubernetes集群是用来存放数据并通知变动的。 Kubernetes中没有用到数据库,它把关键数据都存放在etcd中,这使kubernetes的整体结构变得非常简单。 在kubernetes中,数据是随时发生变化的,比如说用户提交了新任务、增加了新的Node、Node宕机了、容器死掉了等等,都会触发状态数据的变更。 状态数据变更之后呢,Master上的kube-scheduler和kube-controller-manager,就会重新安排工作,它们的工作安排结果也是数据。 这些变化,都需要及时地通知给每一个组件。etcd有一个特别好用的特性,可以调用它的api监听其中的数据,一旦数据发生变化了,就会收到通知。 有了这个特性之后,kubernetes中的每个组件只需要监听etcd中数据,就可以知道自己应该做什么。kube-scheduler和kube-controller-manager呢, 也只需要把最新的工作安排写入到etcd中就可以了,不用自己费心去逐个通知了
全面了解 k8s
想进一步了解更多细节的读者可以继续阅读以下文章:
docker 底层核心技术与实现原理
docker其实是使用了Linux Kernel的一些特性Features来实现的资源隔离,文件系统就是其中一种,但docker为了使资源可以更高效的被利用,采用了分层次的文件系统结构,来实现container的文件系统。
docker 分层机制
docker镜像是一种分层结构,每一层构建在其它层之上,从而实现增量增加内容的功能,这是如何实现的?这里用到了Linux的Union File System分层技术。
Union File System(简称,UnionFS):是为 Linux 系统设计的将其他文件系统联合到一个联合挂载点的文件系统服务。 UnionFS使用 branch(分支)将不同文件系统的文件和目录透明地叠加覆盖,形成一个单一一致的文件系统, 此外 UnionFS 使用写时复制(Copy on Write,简称,CoW)技术来提高合并后文件系统的资源利用。
其实docker镜像分层、增量增加就是利用UnionFS功能,在基础的文件系统上增量的增加新的文件系统, 通过叠加覆盖的形式最终形成一个文件系统,同时这也导致了运行 docker 容器如果没有指定 volume(数据卷)或 bind mount, 则 docker 容器结束后,运行时产生的数据便丢失了(一般会指定宿主主机的目录)。
可以将docker 镜像看成一个整体。所有的docker 镜像都是一个 基础镜像(可以理解为依托点),在基础镜像的层次和基础之上,所做的修改以及增加的功能,都会生成新的一层。 根据这个分层机制可以对特定的镜像进行瘦身优化。
分层好处
- 拉取更快:因为分层了,只需拉取本地不存在的层即可
- 存储更少:因为共同的层只需存储一份即可
- 运行时存储更少:容器运行时可以共享相同的层。多个基于相同镜像运行的容器,都可以直接使用相同的镜像层,每个容器只需一个自己的可写层即可。
容器写策略用的是Copy-on-write,它是一种提高文件共享和复制效率的策略。如果一个文件和目录在低一层的镜像层中存在,并且其它层想要读取这个文件,就直接使用这个文件。 如果其它层想要修改这个文件(不管是构建镜像时,还是在容器运行的过程中),这个文件都会被先拷贝到新的一层中,然后再修改它
总而言之,镜像层是只读的,新的镜像层是基于前一个镜像层的修改,只保留了增量修改的部分! 使用了联合文件系统,对文件系统的修改作为一次提交来一层层的叠加! 容器本质上也是在镜像的基础上加了一层可写层
docker 隔离机制
Linux Namespace是Linux提供的一种内核级别环境隔离的方法。不知道你是否还记得很早以前的Unix有一个叫chroot的系统调用(通过修改根目录把用户jail到一个特定目录下), chroot提供了一种简单的隔离模式:chroot内部的文件系统无法访问外部的内容。Linux Namespace在此基础上,提供了对UTS、IPC、mount、PID、network、User等的隔离机制。
Docker的隔离性主要运用Namespace 技术。传统上Linux中的PID是唯一且独立的,在正常情况下,用户不会看见重复的PID。然而在Docker采用了Namespace, 从而令相同的PID可于不同的Namespace中独立存在。如,A Container 之中PID=1是A程序,而B Container之中的PID=1同样可以是A程序。 虽然Docker可透过Namespace的方式分隔出看似是独立的空间,然而Linux内核(Kernel)却不能Namespace,所以即使有多个Container, 所有的system call其实都是通过主机的内核处理,这便为Docker留下了不可否认的安全问题。docker 主要用到了以下技术实现隔离:
- Linux的Capability机制:capability把权限进行了拆分,可以把部分权限赋予给普通用户进程,而不需要切换到root。
- 写入时复制(Copy-On-Write):所有运行的容器可以先共享一个基本文件系统镜像,一旦需要向文件系统写数据,就引导它写到与该容器相关的另一个特定文件系统中。 这样的机制避免了一个容器看到另一个容器的数据,而且容器也无法通过修改文件系统的内容来影响其他容器。
- NameSpace机制:使用Namespaces实现了系统环境的隔离。Namespace的6项隔离看似完整,实际上依旧没有完全隔离Linux资源, 如
/proc 、/sys 、/dev/sd*等目录未完全隔离,SELinux、time、syslog等信息都未隔离。/proc/[pid]/ns 目录下会包含进程所属的 Namespace 信息,用 ls 命令查看即可。 - CGroups:使用CGroups限制这个环境的资源使用情况。只能限制资源消耗的最大值,而不能隔绝其他程序占用自己的资源
NameSpace机制
man page 中对其有较为简明的阐述。 每种namespace都有对应的id用于该namespace下的唯一标识,防止重复映射。 我们可以到proc下(/proc/进程pid/ns)查看进程的各个namespace的id,用 ls -l /proc/进程pid/ns命令可以查看。 如果两个进程指向的namespace编号相同,就说明他们在同一个namespace下,否则则在不同namespace里面。 namespace 解决了环境隔离和资源名称映射的问题。
1
UTS Namespace:
UTS Namespace 对主机名和域名进行隔离。为什么要隔离主机名?因为主机名可以代替IP来访问。如果不隔离,同名访问会出冲突。
1
IPC Namespace
Linux 提供很多种进程通信机制,IPC Namespace 针对 System V 和 POSIX 消息队列,这些 IPC 机制会使用标识符来区别不同的消息队列, 然后两个进程通过标识符找到对应的消息队列。IPC namespace使得相同的标识符在两个Namespace代表不同的消息队列,因此两个Namespace 中的进程不能通过 IPC 来通信。
1
PID Namespace
PID Namespace 用来隔离进程的 PID 空间,使得不同 PID Namespace 里的进程 PID 可以重复且互不影响。PID Namespace 对容器类应用特别重要, 可以实现容器内进程的暂停/恢复等功能,还可以支持容器在跨主机的迁移前后保持内部进程的 PID 不发生变化。
1
Mount Namespace
Mount Namespace 为进程提供独立的文件系统视图。可以这么理解,Mount Namespace 用来隔离文件系统的挂载点, 这样进程就只能看到自己的Mount Namespace中的文件系统挂载点。 进程的Mount Namespace中的挂载点信息可以在 /proc/[pid]/mounts、/proc/[pid]/mountinfo 和 /proc/[pid]/mountstats 这三个文件中找到。 在一个 Namespace 里挂载、卸载的动作不会影响到其他 Namespace。
1
Network Namespace
Network Namespace 在逻辑上是网络堆栈的一个副本,它有自己的路由、防火墙规则和网络设备。 默认情况下,子进程继承其父进程的 Network Namespace。每个新创建的 Network Namespace 默认有一个本地环回接口 lo, 除此之外,所有的其他网络设备(物理/虚拟网络接口,网桥等)只能属于一个 Network Namespace。每个 socket 也只能属于一个 Network Namespace。 在Linux下,我们一般用ip命令创建Network Namespace(Docker的源码中,它没有用ip命令,而是自己实现了ip命令内的一些功能)。 下面的shell操作基本上就是docker网络的原理了,但具体实现方式有所不同。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
## 首先,我们先增加一个网桥lxcbr0,模仿docker0
brctl addbr lxcbr0
brctl stp lxcbr0 off
ifconfig lxcbr0 192.168.10.1/24 up #为网桥设置IP地址
## 接下来,我们要创建一个network namespace - ns1
# 增加一个namesapce 命令为 ns1 (使用ip netns add命令)
ip netns add ns1
# 激活namespace中的loopback,即127.0.0.1(使用ip netns exec ns1来操作ns1中的命令)
ip netns exec ns1 ip link set dev lo up
## 然后,我们需要增加一对虚拟网卡
# 增加一个pair虚拟网卡,注意其中的veth类型,其中一个网卡要按进容器中
ip link add veth-ns1 type veth peer name lxcbr0.1
# 把 veth-ns1 按到namespace ns1中,这样容器中就会有一个新的网卡了
ip link set veth-ns1 netns ns1
# 把容器里的 veth-ns1改名为 eth0 (容器外会冲突,容器内就不会了)
ip netns exec ns1 ip link set dev veth-ns1 name eth0
# 为容器中的网卡分配一个IP地址,并激活它
ip netns exec ns1 ifconfig eth0 192.168.10.11/24 up
# 上面我们把veth-ns1这个网卡按到了容器中,然后我们要把lxcbr0.1添加上网桥上
brctl addif lxcbr0 lxcbr0.1
# 为容器增加一个路由规则,让容器可以访问外面的网络
ip netns exec ns1 ip route add default via 192.168.10.1
# 在/etc/netns下创建network namespce名称为ns1的目录,
# 然后为这个namespace设置resolv.conf,这样,容器内就可以访问域名了
mkdir -p /etc/netns/ns1
echo "nameserver 8.8.8.8" > /etc/netns/ns1/resolv.conf
无论是Docker的NAT方式,还是混杂模式都会有性能上的问题,NAT不用说了,存在一个转发的开销, 混杂模式呢,网卡上收到的负载都会完全交给所有的虚拟网卡上,于是就算一个网卡上没有数据,但也会被其它网卡上的数据所影响。
这两种方式都不够完美,我们知道,真正解决这种网络问题需要使用VLAN技术,于是Google的开发者为Linux内核实现了一个 IPVLAN 的驱动, 这基本上就是为Docker量身定制的。
1
User Namespace
User Namespace 用于隔离安全相关的资源,包括 user IDs and group IDs,keys, 和 capabilities。 同样一个用户的 user ID 和 group ID 在不同的User Namespace 中可以不一样(与 PID Namespace 类似)。 可以这样理解,一个用户可以在一个User Namespace中是普通用户,但在另一个User Namespace中是root用户。 结合程序的阐述可参考
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
#define _GNU_SOURCE
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <sys/mount.h>
#include <sys/capability.h>
#include <stdio.h>
#include <sched.h>
#include <signal.h>
#include <unistd.h>
#define STACK_SIZE (1024 * 1024)
static char container_stack[STACK_SIZE];
char* const container_args[] = {
"/bin/bash",
NULL
};
int pipefd[2];
void set_map(char* file, int inside_id, int outside_id, int len) {
FILE* mapfd = fopen(file, "w");
if (NULL == mapfd) {
perror("open file error");
return;
}
fprintf(mapfd, "%d %d %d", inside_id, outside_id, len);
fclose(mapfd);
}
void set_uid_map(pid_t pid, int inside_id, int outside_id, int len) {
char file[256];
sprintf(file, "/proc/%d/uid_map", pid);
set_map(file, inside_id, outside_id, len);
}
void set_gid_map(pid_t pid, int inside_id, int outside_id, int len) {
char file[256];
sprintf(file, "/proc/%d/gid_map", pid);
set_map(file, inside_id, outside_id, len);
}
int container_main(void* arg)
{
printf("Container [%5d] - inside the container!\n", getpid());
printf("Container: eUID = %ld; eGID = %ld, UID=%ld, GID=%ld\n",
(long) geteuid(), (long) getegid(), (long) getuid(), (long) getgid());
/* 等待父进程通知后再往下执行(进程间的同步) */
char ch;
close(pipefd[1]);
read(pipefd[0], &ch, 1);
printf("Container [%5d] - setup hostname!\n", getpid());
//set hostname
sethostname("container",10);
//remount "/proc" to make sure the "top" and "ps" show container's information
mount("proc", "/proc", "proc", 0, NULL);
execv(container_args[0], container_args);
printf("Something's wrong!\n");
return 1;
}
int main()
{
const int gid=getgid(), uid=getuid();
printf("Parent: eUID = %ld; eGID = %ld, UID=%ld, GID=%ld\n",
(long) geteuid(), (long) getegid(), (long) getuid(), (long) getgid());
pipe(pipefd);
printf("Parent [%5d] - start a container!\n", getpid());
int container_pid = clone(container_main, container_stack+STACK_SIZE,
CLONE_NEWUTS | CLONE_NEWPID | CLONE_NEWNS | CLONE_NEWUSER | SIGCHLD, NULL);
printf("Parent [%5d] - Container [%5d]!\n", getpid(), container_pid);
//To map the uid/gid,
// we need edit the /proc/PID/uid_map (or /proc/PID/gid_map) in parent
//The file format is
// ID-inside-ns ID-outside-ns length
//if no mapping,
// the uid will be taken from /proc/sys/kernel/overflowuid
// the gid will be taken from /proc/sys/kernel/overflowgid
set_uid_map(container_pid, 0, uid, 1);
set_gid_map(container_pid, 0, gid, 1);
printf("Parent [%5d] - user/group mapping done!\n", getpid());
/* 通知子进程 */
close(pipefd[1]);
waitpid(container_pid, NULL, 0);
printf("Parent - container stopped!\n");
return 0;
}
Namespace 实现
主要是三个系统调用,详细文档在Namespaces in operation:
clone(): 实现线程的系统调用,用来创建一个新的进程,并可以通过设计上述参数达到隔离。unshare(): 使某进程脱离某个namespacesetns(): 把某进程加入到某个namespace
Namespace 种类和以上系统调用的参数对应关系如下:
| 分类 | 系统调用参数 |
|---|---|
| Mount namespaces | CLONE_NEWNS |
| UTS namespaces | CLONE_NEWUTS |
| IPC namespaces | CLONE_NEWIPC |
| PID namespaces | CLONE_NEWPID |
| Network namespaces | CLONE_NEWNET |
| User namespaces | CLONE_NEWUSER |
系统调用参数的使用例子如下,模仿docker实现隔离的详细例子请参阅 DOCKER基础技术:LINUX NAMESPACE(上):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
#define _GNU_SOURCE
#include <sys types.h="">
#include <sys wait.h="">
#include <sys mount.h="">
#include <stdio.h>
#include <sched.h>
#include <signal.h>
#include <unistd.h>
#define STACK_SIZE (1024 * 1024)
static char container_stack[STACK_SIZE];
char* const container_args[] = {
"/bin/bash",
"-l",
NULL
};
int container_main(void* arg)
{
printf("Container [%5d] - inside the container!\n", getpid());
//set hostname
sethostname("container",10);
//remount "/proc" to make sure the "top" and "ps" show container's information
if (mount("proc", "rootfs/proc", "proc", 0, NULL) !=0 ) {
perror("proc");
}
if (mount("sysfs", "rootfs/sys", "sysfs", 0, NULL)!=0) {
perror("sys");
}
if (mount("none", "rootfs/tmp", "tmpfs", 0, NULL)!=0) {
perror("tmp");
}
if (mount("udev", "rootfs/dev", "devtmpfs", 0, NULL)!=0) {
perror("dev");
}
if (mount("devpts", "rootfs/dev/pts", "devpts", 0, NULL)!=0) {
perror("dev/pts");
}
if (mount("shm", "rootfs/dev/shm", "tmpfs", 0, NULL)!=0) {
perror("dev/shm");
}
if (mount("tmpfs", "rootfs/run", "tmpfs", 0, NULL)!=0) {
perror("run");
}
/*
* 模仿Docker的从外向容器里mount相关的配置文件
* 你可以查看:/var/lib/docker/containers/<container_id>/目录,
* 你会看到docker的这些文件的。
*/
if (mount("conf/hosts", "rootfs/etc/hosts", "none", MS_BIND, NULL)!=0 ||
mount("conf/hostname", "rootfs/etc/hostname", "none", MS_BIND, NULL)!=0 ||
mount("conf/resolv.conf", "rootfs/etc/resolv.conf", "none", MS_BIND, NULL)!=0 ) {
perror("conf");
}
/* 模仿docker run命令中的 -v, --volume=[] 参数干的事 */
if (mount("/tmp/t1", "rootfs/mnt", "none", MS_BIND, NULL)!=0) {
perror("mnt");
}
/* chroot 隔离目录 */
if ( chdir("./rootfs") != 0 || chroot("./") != 0 ){
perror("chdir/chroot");
}
execv(container_args[0], container_args);
perror("exec");
printf("Something's wrong!\n");
return 1;
}
int main()
{
printf("Parent [%5d] - start a container!\n", getpid());
int container_pid = clone(container_main, container_stack+STACK_SIZE,
CLONE_NEWUTS | CLONE_NEWIPC | CLONE_NEWPID | CLONE_NEWNS | SIGCHLD, NULL);
waitpid(container_pid, NULL, 0);
printf("Parent - container stopped!\n");
return 0;
}
资源使用限制
Namespace解决的问题主要是环境隔离的问题,这只是虚拟化中最最基础的一步,我们还需要解决对计算机资源使用上的隔离。 这就需要 ```Cgroup`` 技术。
1
Linux CGroup全称Linux Control Group, 是Linux内核的一个功能,用来限制,控制与分离一个进程组群的资源(如CPU、内存、磁盘输入输出等)
Linux 将 CGroup 实现成了一个file system,可以借助 mount 命令使用。 子系统是CGroups中一个重要的概念,子系统可以理解为资源控制器,每种子系统就是一个资源的分配器, 可以独立的控制一种资源。例如CPU子系统就是控制CPU分配的。每一个CGroup下面都有tasks文件,tasks文件中存储着属于当前控制组的所有进程的pid,
如果用户需要控制Docker某个容器的资源占用情况,可以在Docker的控制组下面找到对应的子系统, 并改变对应文件的内容。当然Docker提供了相应的指令在运行容器时由Docker进程去完成相应文件内容的变更; 当我们关闭容器时,Docker子系统对应的文件夹会被Docker进程同步移除。
目前Docker使用了以下几种子系统:
| 子系统 | 功能 |
|---|---|
| blkio | 可以为块设备设定I/O限制 |
| cpu | 可以控制任务对CPU的使用 |
| cpuacct | 记录CPU的使用情况 |
| cpuset | 为任务分配独立的CPU和内存 |
| devices | 开启或关闭对设备的访问 |
| freezer | 可以挂起或恢复任务 |
| memory | 可以设定任务对内存的使用上限,并自动记录内存资源使用情况 |
| perf_event | 可以进行统一的性能检测 |
| net_cls | 使用等级识别符classid标记网络数据包, 允许 Linux 流量控制程序 tc 识别从具体 cgroup 中生成的数据包 |
| net_prio | 设计网络流量的优先级 |
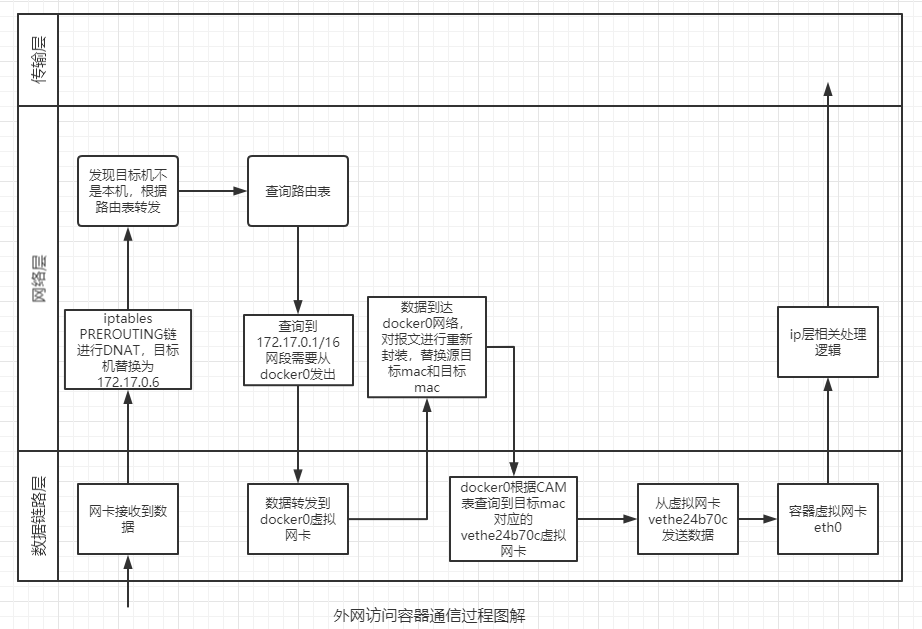
Docker 容器网络通信原理
前面已经提到过,docker 容器可以看做是一个被隔离的进程,可视为一个虚拟化的单机。那么这种虚拟化设备–单机,要想能够连通网络, 则需要独立的网络栈设备(当然这也是虚拟的,需要借助物理机的一些真实设备来完成):
- 网卡(Network Interface)
- 回环设备(Loopback Device)
- 路由表(Routing Table)
- iptables 规则
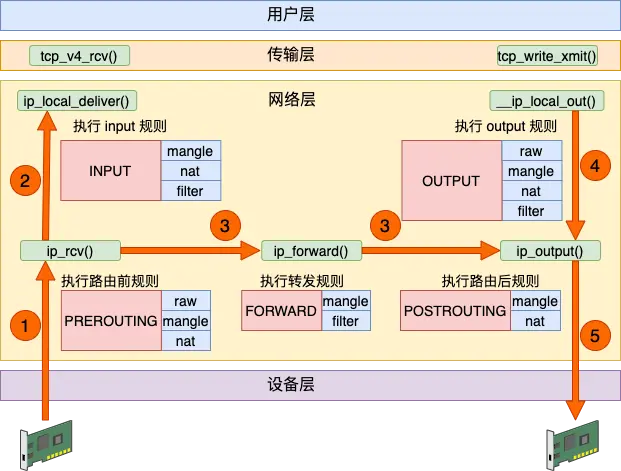
有了这些虚拟设备之后,需要实现以下需求:
- 容器之间通信
- 容器与宿主机之间通信
- 容器与外部主机通信
为实现这些需求,docker 主要提供了以下几种工具:
- network namspace:网络名称空间默认是相互隔离的
- Linux bridge:虽为虚拟网络设备,但其工作方式非常类似于物理的网络交换机设备。
- 可以工作在二次,也可以工作在三层,默认工作在二层。
- 工作在二层时,可以在同一网络的不同主机间转发以太网报文,可以视为小的局域网
- 给 Linux Bridge 分配了 IP 地址之后,其就开启了三层工作模式
- 在 Linux 下,你可以用 proute2 工具包或 brctl 命令对其进行管理
- Veth Pair 设备:它被创建出来后,总是以两张虚拟网卡(Veth Peer)的形式成对出现的。 并且,从其中一个“网卡”发出的数据包,可以直接出现在与它对应的另一张“网 卡”上,哪怕这两个“网卡”在不同的 Network Namespace 里。 这两张网卡都与网桥连通着。
网络模式
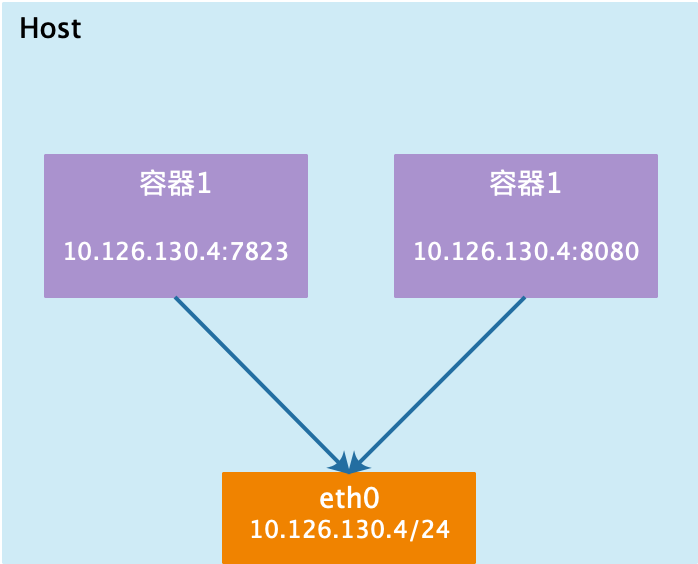
Host 模式
docker不会为容器创建独有的network namespace;使用宿主机的默认网络命名空间,共享一个网络栈; 表现为容器内和宿主机的IP一致;这种模式用于网络性能较高的场景,但安全隔离性相对差一些。
Bridge 模式
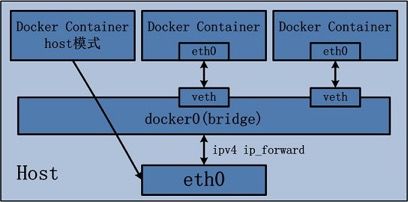
桥接模式,有点类似 VM-NAT,dockerd 进程启动时会创建一个 docker0 网桥,容器内的数据通过这个网卡设备与宿主机进行数据传输。
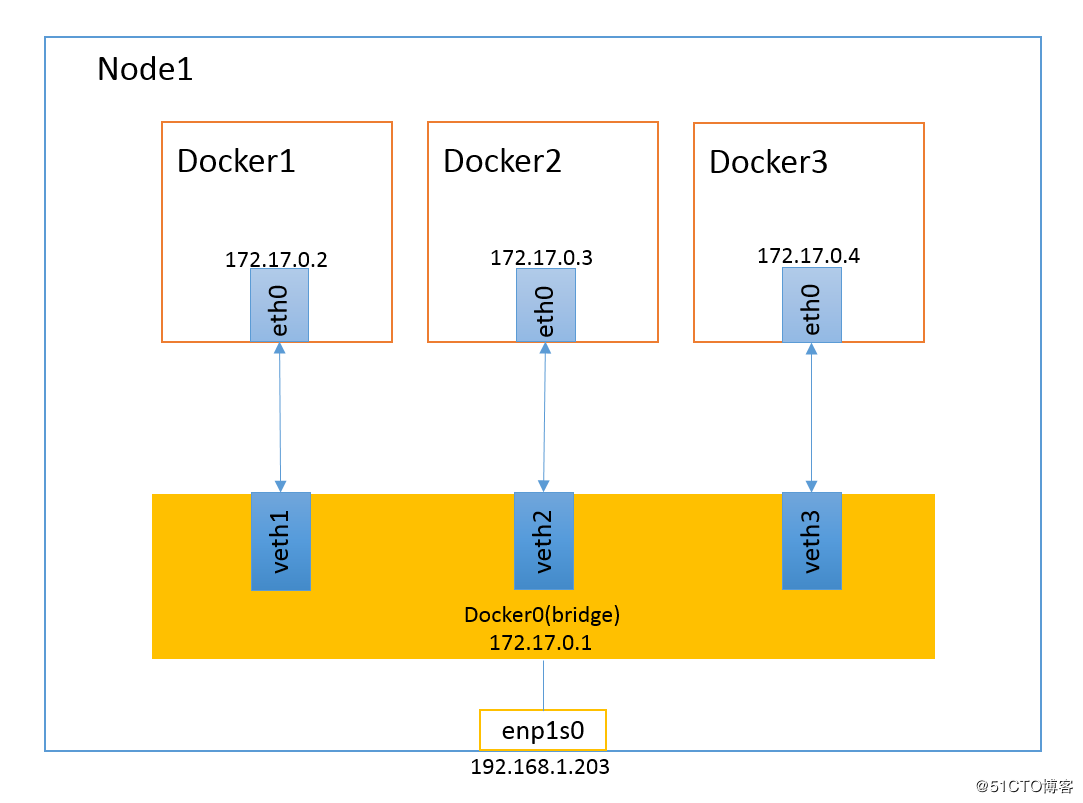
虚拟网桥的工作方式和物理交换机类似,这样主机上的所有容器就通过交换机连在了一个二层网络中。从 docker0 子网中分配一个 IP 给容器使用, 并设置 docker0 的 IP 地址为容器的默认网关。在主机上创建一对虚拟网卡 veth pair 设备,Docker 将 veth pair 设备的一端放在新创建的容器中, 并命名为 eth0(容器的网卡),另一端放在主机中,以 vethxxx 这样类似的名字命名,并将这个网络设备加入到 docker0 网桥中。 bridge 模式是 docker 的默认网络模式,不写 –net 参数,就是 bridge 模式。 使用 docker run -p 时,docker 实际是在 iptables 做了 DNAT 规则,实现端口转发功能。 可以使用 iptables -vnL 查看。 docker 会为容器创建独有的 network namespace,也会为这个命名空间配置好虚拟网卡,路由,DNS,IP地址与iptables规则(也就是sandbox的内容)。
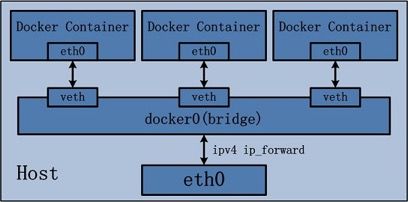
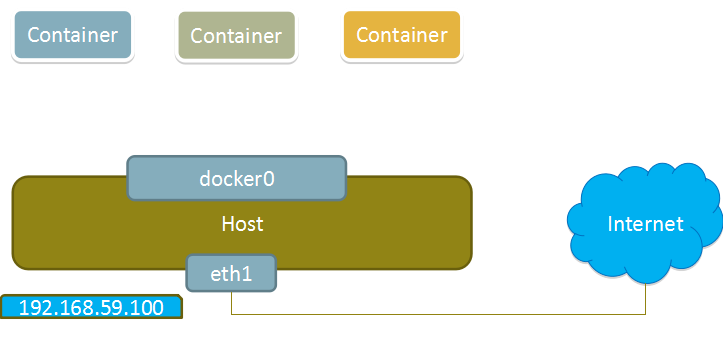
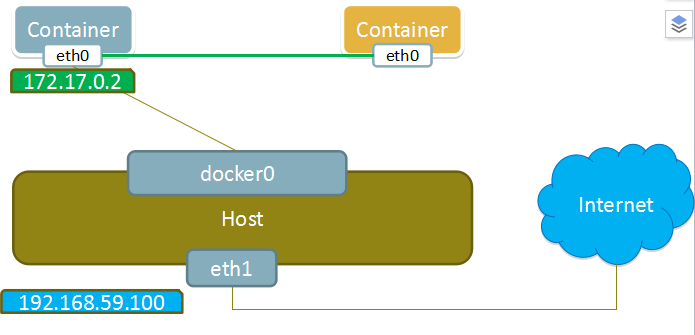
none 模式
使用 none 模式,Docker 容器拥有自己的 Network Namespace,但是,并不为 Docker 容器进行任何网络配置。 也就是说,这个 Docker 容器没有网卡、IP、路由等信息。需要我们自己为 Docker 容器添加网卡、配置 IP 等。
这种网络模式下容器只有 lo 回环网络,没有其他网卡。none 模式可以在容器创建时通过 –network=none 来指定。 这种类型的网络没有办法联网,封闭的网络能很好的保证容器的安全性。
joined-container 模式
这个模式指定新创建的容器和已经存在的一个容器共享一个 Network Namespace,而不是和宿主机共享。新创建的容器不会创建自己的网卡,配置自己的 IP, 而是和一个指定的容器共享 IP、端口范围等。同样,两个容器除了网络方面,其他的如文件系统、进程列表等还是隔离的。两个容器的进程可以通过 lo 网卡设备通信。 这种模式是host模式的一种延伸。
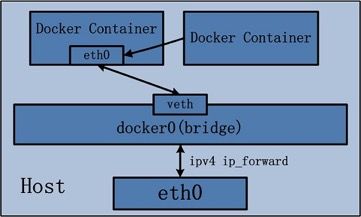
容器之间通信
前面我们提到一个概念,把容器作为单机来看。其实不同容器之间的通信,类似于不同主机之间的通信。 两台主机连接只需要一个网线即可;多台主机则需要多根网线实现,网线的一端连接主机,另一端连接 在一台交换机上。在 Linux 中对应的虚拟设备是
- docker0 是 docker 容器之间的网桥
- Veth Pair 相当于网线,把容器连接到 docker0 网桥上
容器中的虚拟网卡是一个 Veth Pair,它的一端在这个容器的 Network Namespace 里,另一端则位于 宿主机上(Host Namespace),这类似物理网线,网线汇集在了宿主机的 docker0 网桥上。
一旦一张虚拟网卡被“插”在网桥上,它就会变成该网桥的“从设备”。从设备会被“剥夺”调用网络协议栈处理数据包的资格, 从而“降级”成为网桥上的一个端口。而这个端口唯一的作用,就是接收流入的数据包, 然后把这些数据包的“生杀大权”(比如转发或者丢弃),全部交给对应的网桥。
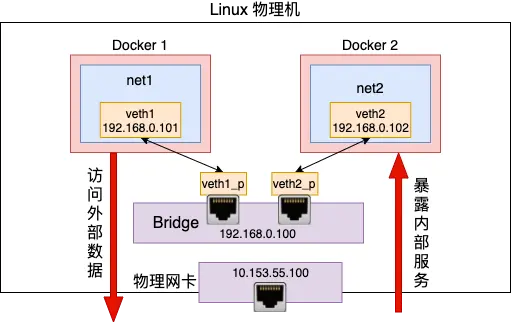
容器间通信的大致流程:
- 容器 A 首先查看自己的路由表,拿到连通容器 B 的那条路由(此路由一般经过本机的 eth0 网卡,通过二层网络直接发往目的主机,无需 gateway 转发便可以直接将数据包送达)
- 容器 A 向 B 绑定的 IP(路由中有 IP 信息)发起 ARP 请求,查询容器 B 的 mac 地址(要么从 arp cache 中找到,要么在 docker0 这个二层交换机中泛洪查询)
- 容器 A 把数据包发往容器 B 的 mac 地址(即 B 的虚拟网卡)即可。这可类比局域网中两台主机间的通信。实际上是直连网络,实质上是 docker0 在二层起到的作用。
容器与宿主机之间通信
容器与宿主机之间的通信类似容器之间的通信,只不过宿主机属于 Host Namespace,而容器属于各自的 Namespace。 docker0 连通了 Host Namespace 和 容器的 Namespace 的,也就是充当着网桥的作用。因此宿主机通过 docker0(在 Host Namespace 中)抽象后 相当于一个特殊的”容器“,其通信机制可以参考容器之间通信。
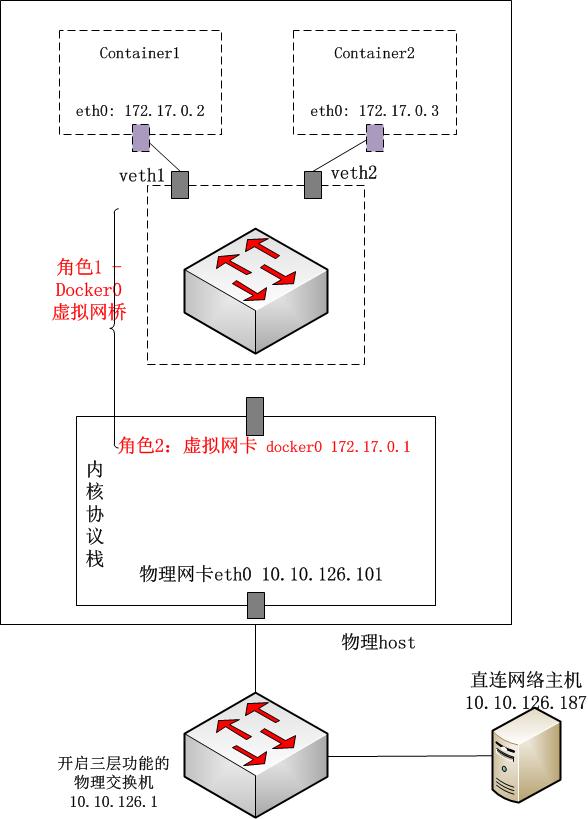
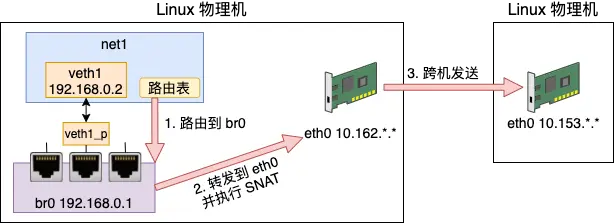
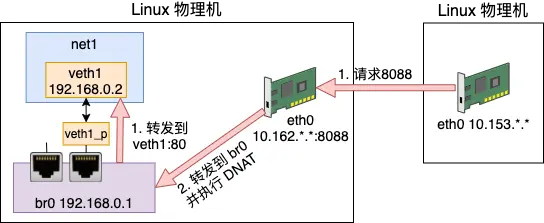
容器与外网通信
容器跨主机通信有多种方案,不论哪种方案都要确保:
- 处于外网中时,有自己或者自己组织的有效 IP
- 处于局域网中时,有自己独有的内网 IP
- 外网能识别的 IP 和 内网 IP 有映射关系
以上几个条件都是为了数据包在主机内部能够有效转发,需要有有 IP 和端口。由于已经在主机内部,这里的 IP 和端口可以是虚拟的,不需要全网唯一,只要 能够找到对应关系到达容器或应用程序即可。不过需要指出的是,这种容器与外网间的通信方式免不了会多转发几次,在网络性能上是有损耗的。在这种机制中, namespace命名空间起到了至关重要的作用,相当于主机内重用了 IP 和端口,从而不需要改变原有的基础设施。