本文通过讲解或制造bug来学习原理。并得到相应的优化手段。
测试工具
测试在原型开发和实际开发、bug复现和技术学习等中,都至关重要。因此,掌握适当的工具,可以简化测试,提高测试效率, 进而使测试起来简单、可复用。也就使开发人员更容易和愿意去做这种保质且划算的测试。
以下列举的单元测试工具展示了一个发展流程,对于非mock测试:
- 简单断言或结果打印,可使用
官方原生测试包 - 含各场景分组测试、可读性强、长期维护的测试用例,复杂断言等,可使用
testfy(推荐)
这里简单总结一下几个测试框架:个人觉得 GoConvey 的语法 对业务代码侵入有点严重, 而且理解它本身也需要一些时间成本,比如 testify 逻辑清晰。单元测试逻辑本身就要求比较简单, 综上,还是更推荐用 testify。
官方原生测试包
在testing包中包含一下结构体:
testing.T: 这就是我们平常使用的单元测试testing.F: 模糊测试, 可以自动生成测试用例testing.B: 基准测试. 对函数的运行时间进行统计.testing.M: 测试的钩子函数, 可预置测试前后的操作.testing.PB: 测试时并行执行.
1
2
3
4
5
6
7
8
9
10
// 此方法源自 Go 官方文档
func Reverse(s string) string {
bs := []byte(s)
length := len(bs)
for i := 0; i < length/2; i++ {
bs[i], bs[length-i-1] = bs[length-i-1], bs[i]
}
return string(bs)
}
testing.T
Go对单元测试函数要求如下
- 文件名形如:
xxx_test.go - 函数签名形如:
func TestXxx(t *testing.T)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
func TestReverse(t *testing.T) {
str := "abc"
revStr1 := Reverse(str)
revStr2 := Reverse(revStr1)
if str != revStr2 {
// error 方法报错后, 会继续向下执行
t.Error("error")
// fatal 方法报错后, 会退出测试
// t.Fatal("fatal")
// 输出调试信息
// t.Log("log")
// 测试中断, 但是测试结果不会十遍
// t.Skip("skip")
}
// 可启动多个子测试, 子测试之间并行运行
for _, str = range []string{"abcd", "aceb"} {
// 第一个参数为子测试的标识
t.Run(str, func(t *testing.T) {
revStr1 := Reverse(str)
revStr2 := Reverse(revStr1)
if str != revStr2 {
t.Error("error")
}
})
}
}
下面将要测试的每种情况列举出来,然后针对每个整数调用ToRoman()函数,比较返回的罗马数字字符串和错误值是否与预期的相符。后续要添加新的测试用例也很方便。 表格驱动测试示例如下(表驱动测试中testCases结构中加一个场景描述字段,可以提高可读性):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
func TestToRoman(t *testing.T) {
testCases := []struct {
num int
expect string
err error
}{
{0, "", ErrOutOfRange},
{1, "I", nil},
{500, "D", nil},
{1000, "M", nil},
{31, "XXXI", nil},
{312, "CCCXII", nil},
{4000, "", ErrOutOfRange},
}
for _, testCase := range testCases {
got, err := ToRoman(testCase.num)
if got != testCase.expect {
t.Errorf("ToRoman(%d) expect:%s got:%s", testCase.num, testCase.expect, got)
}
if err != testCase.err {
t.Errorf("ToRoman(%d) expect error:%v got:%v", testCase.num, testCase.err, err)
}
}
}
有时候对同一个函数有不同维度的测试,将这些组合在一起有利于维护。例如上面对ToRoman()函数的测试可以分为非法值,单个罗马字符和普通 3 种情况。
使用如下命令运行测试用例(test.run 指定运行某一个函数):
1
go test -test.run TestReverse
testing.F
用于模糊测试, 会自动生成测试用例。其内部会自动生成各种测试用例, 并自动调用执行。 Go对模糊测试的函数要求如下:
- 文件名形如:
xxx_test.go - 函数签名形如:
func FuzzXxx(f *testing.F)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
func FuzzReverse(f *testing.F) {
// 设置测试用例需要随机生成的变量类型
f.Add("Hello, world!")
// 生成测试用例并进行测试. 回电函数接收的参数, 与 f.Add 设置的参数类型一致
f.Fuzz(func(t *testing.T, str string) {
revStr1 := Reverse(str)
revStr2 := Reverse(revStr1)
if revStr2 != str {
t.Error("error")
}
// 判断是否是合法的 utf8 编码
if utf8.ValidString(str) && !utf8.ValidString(revStr1) {
t.Error("utf8 error")
}
})
}
运行命令开始测试: go test -test.fuzz FuzzReverse -test.run ^$ (其中test.run指定不运行test函数)。 模糊测试的难点在于,即使测试用例是随机的,也需要像上面示例那样有办法验证其正确性。
testing.B
用于基准测试. 对函数的运行时间进行统计, 对函数要求如下:
- 文件名形如:
xxx_test.go - 函数签名形如:
func BenchmarkXxx(b *testing.B)
运行命令: go test -test.bench BenchmarkReverse -test.run ^$
结果中指出了运行次数及平均时间. 其中各项值的含义如下:
- 100000000: 迭代次数
- ns/op: 平均每次迭代消耗的时间
- B/op: 平均每次迭代消耗的内存
- allocs/op: 平均每次迭代内存的分配次数
testing.M
定义在运行测试的前后执行的操作. 对函数的要求如下:
- 文件名形如:
xxx_test.go - 函数签名为:
func TestMain(m *testing.M)
函数定义如下:
1
2
3
4
5
6
7
8
9
func TestMain(m *testing.M) {
// 测试之前执行的操作
fmt.Println("starting test main")
// 运行测试
code := m.Run()
// 测试之后执行的操作
fmt.Println("ending test main")
os.Exit(code)
}
此函数会在运行所有测试时自动调用.
testing.PB
用于在测试时进行并发测试. 上面的”单元测试/模糊测试/基准测试”都可以使用. 以基准测试为例, 使用如下:
1
2
3
4
5
6
7
8
9
10
// 充分利用 CPU 资源, 并行执行 n 次
func BenchmarkReverse2(b *testing.B) {
b.RunParallel(func(pb *testing.PB) {
for pb.Next() {
// 此循环体总共执行 b.N 次
Reverse("hello")
}
})
}
testdata 目录和 Golden 文件
这个也是一个比较特殊的目录,go build 编译时,会自动忽略 testdata 目录, 并且在运行 go test 指令时,会将 test 文件所在目录设置为根目录, 可以直接使用相对路径 testdata 引入或者存储相关文件。
简而言之,testdata 目录的使用场景,就是能够很直观的通过文件内容对比, 发现测试结果是否符合预期,适用于输入输出都比较复杂的情况。
go 官方标准库 cmd/gofmt/gofmt_test.go 源码中就有用到,可参考。
我们可以将期望输出存储在一个名为 .golden 的文件中并提供一个 flag 来更新它。 这个技巧使你得以测试复杂的输出而无需硬编码。这里是例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
var update = flag.Bool("update", false, "update .golden files")
func TestSomething(t *testing.T) {
actual := doSomething()
Golden := filepath.Join("testdata", tc.Name+ ".golden" )
if *update {
ioutil.WriteFile(golden, actual, 0644)
}
expected, _ := ioutil.ReadFile(golden)
if !bytes.Equal(actual, expected) {
// FAIL!
}
}
帮助函数
Helper()函数将当前所在的函数标记为测试帮助方法。当打印文件和代码行信息时,该方法会被跳过。 Go 语言在 1.9 版本中引入了 t.Helper(),用于标注该函数是帮助函数,报错时将输出帮助函数调用者的信息,而不是帮助函数的内部信息。
关于 helper 函数的 2 个建议:
- 不要返回错误, 帮助函数内部直接使用 t.Error 或 t.Fatal 即可,在用例主逻辑中不会因为太多的错误处理代码,影响可读性。
- 调用 t.Helper() 让报错信息更准确,有助于定位。
示例文件
测试工具包还能运行和验证示例代码。示例函数包含一个结论行注释,该注释以Output:开头,然后比较示例函数的标准输出和注释中的内容。
1
2
3
4
5
6
7
8
9
10
11
12
func ExampleHello() {
fmt.Println("hello")
// Output: hello
}
func ExampleSalutations() {
fmt.Println("hello, and")
fmt.Println("goodbye")
// Output:
// hello, and
// goodbye
}
Unordered output的前缀注释将匹配任意的行顺序。
1
2
3
4
5
6
7
8
9
10
func ExamplePerm() {
for _, value := range Perm(5) {
fmt.Println(value)
}
// Unordered output: 4
// 2
// 1
// 3
// 0
}
不包含output注释的示例函数,将不会被执行。
跳过函数
功能测试或性能测试时可以跳过一些测试函数。
1
2
3
4
5
6
func TestTimeConsuming(t *testing.T) {
if testing.Short() {
t.Skip("skipping test in short mode.")
}
...
}
并发测试
对于表驱动测试和子测试等,可以通过函数标记来进行并发测试。
1
2
3
4
5
6
7
var Cash = make(map[string]string)
func Add(key,value string){
if _,ok := Cash[key];!ok{
Cash[key] = value
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
func TestCanParallelExecAdd(t *testing.T){
var addTests = []struct{
key string
value string
expected int
}{
{"a","aa",1},
{"b","bb",2},
{"c","cc",3},
{"c","cc",3},
{"c","cc",3},
{"d","dd",4},
{"e","ee",5},
{"f","ff",6},
{"g","gg",7},
{"h","hh",8},
{"i","ii",9},
{"j","jj",10},
}
t.Parallel()
quary := rand.Int()
t.Logf("[goroutine:%d] start",quary)
for _,v := range addTests{
Add(v.key,v.value)
t.Logf("[goroutine:%d] add %s:%s",quary,v.key,v.value)
if len(Cash) != v.expected{
t.Errorf("add %s:%s len = %d; except %d",v.key,v.value,len(Cash),v.expected)
}
}
Clean()
}
1
2
3
4
5
6
7
8
func TestParallelAdd(t *testing.T){
for i:=0;i<10;i++{
t.Run(fmt.Sprintf("g-%d",i), func(t *testing.T) {
t.Parallel()
TestAdd(t)
})
}
}
testfy
上节中官方原生测试包简单明了,但缺少很多高效简便的断言。testfy 在兼容官方原生测试包的 同时提供了简便的断言,提高了测试编码效率。
testify 有三个主要功能:
- 断言,在 assert 包和 require 包。
- Mocking,在 mock 包下。
- 测试组件,在 suite 包下。
mock 简易使用 gomonkey,因此减少testfy时不讲其mock功能。
assert 包
assert 包提供了一系列很方便的断言方法,简化你的测试代码。如
1
2
3
4
5
6
7
8
9
10
11
12
13
14
package yours
import (
"testing"
"github.com/stretchr/testify/assert"
)
func TestSomething(t *testing.T) {
// 断言相等
assert.Equal(t, 123, 123, "they should be equal")
// 断言不等
assert.NotEqual(t, 123, 456, "they should not be equal")
// 断言为 nil
assert.Nil(t, object)
}
assert 包的函数的第一个参数为 testing.T,用于执行 go test 时输出信息。 如果你有很多个断言,可以调用New方法实例化 Assertions 结构体,然后就可以省略testing.T参数了。上面的代码,可以简化成
1
2
3
4
5
6
7
8
9
10
func TestSomething(t *testing.T) {
// 实例化 assertion 结构体,下面的断言都不用传入 t 作为第一个参数了。
assert := assert.New(t)
// 断言相等
assert.Equal(123, 123, "they should be equal")
// 断言不等
assert.NotEqual(123, 456, "they should not be equal")
// 断言为 nil
assert.Nil(object)
}
assert 失败的话,底层调用 t.Errorf 来输出错误信息。也就是说,断言失败并不会中停止测试。 assert 包的断言函数,返回值是 bool 类型,表示断言的成功或失败。 我们可以根据返回值,进一步做断言。如
1
2
3
4
// 当 object 不为 nil 的时候,进一步断言 object.Value 的值
if assert.NotNil(t, object) {
assert.Equal(t, "Something", object.Value)
}
assert 包提供的断言类型非常多,包括对比变量、json、目录、Http 响应等。 完整列表见assert
require 包
require 包提供的函数和 assert 包是一样的,区别是:
- require 包如果断言失败,底层调用 t.FailNow, 会立刻中断当前的测试,所以也不会有返回值。
- assert 包如果断言失败,底层调用 t.Errorf,返回 false,不会中断测试。
测试套件 suite
如果你有别的面向对象语言的经验,用 suite 包写单元测试可能更符合你的习惯。 我们可以自定义一个结构体,它依赖 suite.Suite,它所有的以 Test 开头的函数,都是一个测试。 详见suite
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
import (
"testing"
"github.com/stretchr/testify/assert"
"github.com/stretchr/testify/suite"
"fmt"
)
// 依赖 suite.Suite
type ExampleTestSuite struct {
suite.Suite
VariableThatShouldStartAtFive int
}
// 每个测试运行前,会执行
func (suite *ExampleTestSuite) SetupTest() {
suite.VariableThatShouldStartAtFive = 5
}
// 每个测试运行后,会执行
func (suite *ExampleTestSuite) TearDownTest() {
fmt.Println("next test")
}
// 所有以“Test”开头的方法,都是一个测试
func (suite *ExampleTestSuite) TestExample() {
assert.Equal(suite.T(), 5, suite.VariableThatShouldStartAtFive)
}
// 用于 'go test' 的入口
func TestExampleTestSuite(t *testing.T) {
suite.Run(t, new(ExampleTestSuite))
}
suite 中有以下钩子:
- SetupTest:每个测试运行前,都会执行
- TearDownTest: 每个测试之后,都会执行
- SetupSuite: Suite 开始之前执行一次,在所有测试之前执行
- TearDownSuite: Suite 结束之后执行一次,在所有测试之后执行
goconvey
goconvey特别适合于BDD(行为驱动开发)。
行为驱动开发(Behavior Driven Development,BDD)借鉴了敏捷和精益实践, 让敏捷研发团队尽可能理解产品经理或业务人员的产品需求, 并在软件研发过程中及时反馈和演示软件产品的研发状态, 让产品经理或业务人员根据获得的产品研发信息及时对软件产品特性进行调整。 BDD帮助敏捷研发团队把精力集中在识别、理解和构建跟业务目标有关的产品特性上面, 并让敏捷研发团队能够确保识别出的产品特性能够被正确设计和实现出来。
BDD的产品研发流程如下:
- 产品经理(业务人员)通过具体的用户故事使用场景来告诉软件需求分析人员他(她)想要什么样的软件产品。 使用软件产品的使用场景来描述软件需求可以尽可能的避免相关人员错误理解软件需求或增加自己的主观想象的需求。
- 软件需求分析人员(BA)和研发团队(研发人员、测试人员)一起对产品经理(业务人员)的用户故事进行分析, 并梳理出具体的软件产品使用场景举例,这些场景举例使用结构化的关键字自然语言进行描述,例如中文、英文等。
- 研发团队使用BDD工具把用户故事场景文件转化为可执行的自动化测试代码, 研发人员运行自动化测试用例来验证开发出来的软件产品是否符合用户故事场景的验收要求。
- 测试人员可以根据自动化测试结果开展手工测试和探索性测试。
产品经理(业务人员)可以实时查看软件研发团队的自动化测试结果和BDD工具生成的测试报告,确保软件实现符合产品经理(业务人员)的软件期望。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
// split.go
package goconvey_demo
import "strings"
// Split
// @Description: 把字符串s按照给定的分隔符sep进行分割返回字符串切片
// @param s
// @param sep
// @return result
//
func Split(s, sep string) (result []string) {
result = make([]string, 0, strings.Count(s, sep)+1)
i := strings.Index(s, sep)
for i > -1 {
result = append(result, s[:i])
s = s[i+len(sep):] // 使用len(sep)获取sep的长度
i = strings.Index(s, sep)
}
result = append(result, s)
return
}
普通测试文件如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
// split_test.go
import (
"testing"
c "github.com/smartystreets/goconvey/convey" // 别名导入
)
func TestSplit(t *testing.T) {
c.Convey("基础用例", t, func() {
var (
s = "a:b:c"
sep = ":"
expect = []string{"a", "b", "c"}
)
got := Split(s, sep)
c.So(got, c.ShouldResemble, expect) // 断言
})
c.Convey("不包含分隔符用例", t, func() {
var (
s = "a:b:c"
sep = "|"
expect = []string{"a:b:c"}
)
got := Split(s, sep)
c.So(got, c.ShouldResemble, expect) // 断言
})
}
goconvey还支持在单元测试中根据需要嵌套调用和表格驱动,比如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
//
// TestChildrenSplit
// @Description: 嵌套调用
// @param t
//
func TestChildrenSplit(t *testing.T) {
// 只需要在顶层的Convey调用时传入t
c.Convey("分隔符在开头或者结尾用例", t, func() {
tt := []struct {
name string
s string
sep string
expect []string
}{
{"分隔符在开头", "1*2*3", "*", []string{"", "1", "2", "3"}},
{"分隔符在结尾", "1+2+3+", "+", []string{"1", "2", "3", ""}},
}
for _, tc := range tt {
c.Convey(tc.name, func() {
// 嵌套调用Convery
got := Split(tc.s, tc.sep)
c.So(got, c.ShouldResemble, tc.expect)
})
}
})
}
GoConvey为我们提供了很多种类断言方法在So()函数中使用。
- 一般相等类
- 数字数量比较类
- 包含类
- 字符串类
- panic类
- 类型检查类
- 时间和时间间隔类
如果上面列出来的断言方法都不能满足你的需要,那么你还可以按照下面的格式自定义一个断言方法。 除此之外,你还可以借助比如testfy的asset等第三方包。
1
2
3
4
5
6
7
// 注意:<>中的内容是你需要按照实际需求替换的内容。
func should<do-something>(actual interface{}, expected ...interface{}) string {
if <some-important-condition-is-met(actual, expected)> {
return "" // 返回空字符串表示断言通过
}
return "<一些描述性消息详细说明断言失败的原因...>"
}
goconvey提供全自动的WebUI,只需要在项目目录下执行以下命令:goconvey。 默认就会在本机的8080端口提供WebUI界面,十分清晰地展现当前项目的单元测试数据。
mock测试
单元测试一般仅限于测试本服务,对于别的服务的调用(比如数据库), 我们可以创建 Mock 对象来模拟对其他服务的调用。
什么时候适合 mock? 如果一个对象具有以下特征,比较适合使用 mock 对象:
- 该对象提供非确定的结果(比如当前的时间或者当前的温度)
- 对象的某些状态难以创建或者重现(比如网络错误或者文件读写错误)
- 对象方法上的执行太慢(比如在测试开始之前初始化数据库)
- 该对象还不存在或者其行为可能发生变化(比如测试驱动开发中驱动创建新的类)
- 该对象必须包含一些专门为测试准备的数据或者方法(后者不适用于静态类型的语言,流行的 mock 框架不能为对象添加新的方法, stub 是可以的)。
因此,不要滥用 mock(stub),当被测方法中调用其他方法函数,第一反应应该走进去串起来,而不是从根部就 mock掉了。
mock测试的缺陷
- 漏测关键逻辑:任何时候都要小心,被mock的对象其行为未必跟我们预期的一致(比如时区等)。
- 测试不存在的逻辑:mock的时候可能已经满足了某些前提,或者引入了额外的逻辑,而这些前提在实际中可能不存在。
- 漏测横切特性
- 掩盖坏味道:需要mock,可能是
- 依赖过多
- 依赖过于分散:外部依赖没有恰当的封装和隔离
- 依赖的传递方式或隔离方式存在优化空间
- 过长的调用链
- 掩盖性能缺陷:mock一般是直接返回结果,这很可能掩盖了被mock对象或函数的性能缺陷。
- 阻碍重构:强依赖mock,不便于测试,说明代码布局或分拆存在问题,应当优化功能划分或代码封装粒度等。
- 测试实现细节而非功能:应当测试功能或业务逻辑,而不是实现细节。
单元测试是测试细节,但是测试的是业务细节,而不是实现细节。从测试的目的看,任何测试都应该是行为测试 或者业务逻辑测试。即我们测试的是系统或者组件有没有按照期望的方式返回结果。至于这个结果是怎么产生的 不应当是测试负责验证的事情(比如可以借用程序调试)。
值得指出的是,业务逻辑是层层下放的,也就是上一层的所有业务细节,一定在下一层有支撑。而一般情况下每一个方法 一定是应对一个业务需求(粒度大小不同)。
从投入产出比来看,为什么不要测试实现细节呢?
- 实现细节变化快于其实现的业务变化频率,测试成本高;
- 同时,因为测试没有到达“边界”,实际上我们获得的信息是有限的。我们经常会发现测试基本上是在重复已实现的逻辑。
不用Mock怎么写(单元)测试
- 消除『单元』情结:
- 在很多人看来,单元测试就是测试一个类,甚至是一个方法。所有其他的因素全都应当屏蔽掉。 这不仅在原则上是错误的,实践上也几乎是不可能做到的。正确的测试单元应当是一个业务逻辑单元。
- 你的测试本身,而不仅是测试的方法名,应该是对于非开发人员也尽量是可读的。
- 对象创建与依赖注入:尽量通过函数参数(可以是结构体)把依赖传入,而不是在函数内部直接调用依赖(比如单例调用)。
- 考虑其他的间接测试方式: 变换测试粒度,或者间接测试等
- 文件、网络和数据库
- 可以尝试内存数据库或者docker容器
- 网络也有本地可执行的组件等替代手段,或者服务器上真实跑跑和观察更划算
- 文件也可采用内存文件系统,或者服务器上真实跑跑和观察更划算
- MVC和容器
- Reactive Programming:
- 响应式编程孤立尽量避免副作用,这使得一个方法几乎不会对外产生依赖。如果有依赖,也是另一个无副作用的依赖。
- 对于一个函数来说,一个输入无条件的对应一个确定的输出。所以,我们设计的方法往往很快到达“边界”。
在纯粹的Functional Programming中,是不存在面向对象意义上的“对象”的。用户可以定义数据结构,其目的是作为参数 或者结果,而不是将操作和被操作的数据放到一起。从面向对象编程转向响应式编程的思维方式是一个非常大的转变。我们 也不能针对一个用面向对象思维设计出来的类以响应式编程的方式进行测试。
对于中间件的输入和输出可以通过依赖注入(比如mysql的连接通过函数参数或者结构体成员变量注入)和本地docker容器 来实施。而中间件所需的输入数据,可以通过数据文件或shell等脚本批量执行(可以不断复用)。
单元测试的粒度选择可参考玩转Go单元测试,你只需要掌握这5点
业务测试
对于业务测试,可以使用类似配置文件的方式进行代码设计与测试:
- 除了main入口之外,其中所有的业务代码和测试代码都共用
- 正常的代码和测试代码分开文件夹存放
- 正常代码和测试代码入口分别是:main.go 和 test_main.go
- main.go 和 test_main.go 中的主要代码流程也相同,只是参数或配置不同
- 参数或依赖注入的不同主要表现在:
- 外部依赖的mock文件放在测试文件夹中
- 正常代码中要给出可以适配测试的初始化函数,比如文件路径、定时器时间周期等
- 通过第一步之后,制造适当输入即可覆盖所有正常场景和异常场景
- 如果输出也有依赖的话(比如输出到mq或数据库),可以讲输出适配成log,通过log来查看输出
- 通过前面的步骤,就实现了输入和输出的隔离,不依赖任何外部程序的动态数据(依赖的可编译的第三方静态代码是没有任何问题的),可以达到:
- 本地编译和无网络运行
- 测试和正常代码除了输入和输出有mock或不同外,中间的几乎所有的代码逻辑都是共用的
- 本地测试可代替大部分服务器上的测试,而小部分可通过以下过程实现:
- 输入源输出目的地以及其他动态依赖可通过集成测试实现
- 开发之间的协议上的理解、产品与开发之间在业务场景理解上的差异,也是可以通过集成测试交互来识别或协同
- 这种测试的好处:
- 可快速确保自身业务代码的测试覆盖率、测试简便性、测试的可复用性
- 当业务逻辑发生变化时,只要外部依赖没有变化,那么测试代码基本上可复用(相较于每个函数的单元测试而言,测试代码变化的概率要小得多)
- 节约开发在测试上花费的时间,也大大减少了代码更新后的测试与维护时间
- 容易做自身业务代码的性能测试,使自身代码最优化后,也更容易发现集成性能瓶颈点
- 对于特别复杂的函数或算法而言,在尽量拆解复杂性之后,可以通过针对性的单元测试或调试来保证稳健性。
gomonkey
在不得已用 mock 的情况下,推荐使用 gomonkey 这个 mock 工具。 gomonkey 基础特性列表如下:
- 支持为一个函数打一个桩
- 支持为一个成员方法打一个桩
- 支持为一个全局变量打一个桩
- 支持为一个函数变量打一个桩
- 支持为一个函数打一个特定的桩序列
- 支持为一个成员方法打一个特定的桩序列
- 支持为一个函数变量打一个特定的桩序列
具体可参考以下文章:
- gomonkey源码解读
- 你该刷新 gomonkey 的惯用法了
- Golang Mock使用入门
- GoMock快速上手教程
- Go语言如何在没有实现功能的情况下写出完善的单元测试代码
- 如何写出可测试的 Go 代码
mock易用工具
- dockertest
- orlangure/gnomock:各种中间件的mock,单元测试或集成测试时不再需要自己写mock了
- Redis
- Memcached
- MySQL
- MariaDB
- PostgreSQL
- MongoDB
- RabbitMQ
- Kafka
- Elasticsearch
- alicebob/miniredis:纯go的用于单测的redis服务端代码
- cjsaylor/sqlfixture:纯go的用于单测的mysql服务端代码
- k1LoW/grpcstub:grpc测试打桩
其他参考文献
- go test 的使用
- Go单元测试实践
- Go 测试高级窍门和技巧
- Go 全场景测试工具和实践选型推荐
- Go 中的进阶测试模式
- 手把手教你如何进行 Golang 单元测试
- GoLang 单元测试打桩和 mock
- Go单元测试实践
- Golang 单元测试:有哪些误区和实践?
- Golang 单元测试指引
- Go:基于BDD的测试框架 Ginkgo 简介及实践
- 高效测试框架推荐之Ginkgo
- Go 写测试必学的三个库:Ginkgo、testify 和 GoMock
- Ginkgo 测试框架学习笔记
- ginkgo 测试库
- Golang Testing 概览 - 基本篇
- Golang Testing 概览 - 深入篇
- Golang Testing 概览 - 补充篇
- Go单测从零到溜系列0—单元测试基础
- Go单测从零到溜系列1—网络测试
- Go单测从零到溜系列2—MySQL和Redis测试
- Go单测从零到溜系列3—mock接口测试
- Go单测从零到溜系列4—使用monkey打桩
- Go单测从零到溜系列5—goconvey的使用
- Go单测从零到溜系列6—编写可测试的代码
- 使用Go做测试(进阶版)
- 手把手教你如何进行 Golang 单元测试
- 为 go 遗留代码添加单元测试(零)
- Go语言如何在没有实现功能的情况下写出完善的单元测试代码
- Go:测试库(GoConvey,testify,GoStub,GoMonkey)对比及简介
性能检测工具
编码和单元测试一般聚焦在功能正确这个角度,但有时我们需要再有限资源下追求高性能(比如尽量减少CPU和内存占用、降低时延等), 此时就需要借助性能检测工具,以找出性能瓶颈点,然后重点优化。练习pprof的使用可以点击pprof练习
pprof
pprof 可以分析golang运行中的程序或者特定函数的性能数据,比如CPU、内存、协程等资源使用情况,以及各函数使用资源的占比等。 可通过 go install github.com/google/pprof 来安装 pprof。然后可以通过命令 go tool pprof 进行分析。 该命令支持多种数据源和交互模式:
- 数据源:
- http 地址
- 已经采集并下载下来的 profile 文件: pprof -http=:8080 cpu.prof
- 交互模式:
- 命令行交互
- 浏览器模式(-http参数)
如果要用到可视化界面的,需要安装 graphviz
使用场景
一般的使用场景有以下几个:
- 服务器程序(不主动退出)
- 非持续运行的程序(运行短暂时间后会主动退出)
- 测试代码(go test)
已服务器程序为例。通过http采样收集一段时间后,得到相关数据然后就地分析或下载文件后他处分析。要点如下:
- 代码中引入: import _ “net/http/pprof”
- 如果程序中没有现有的 http 端口或服务,需启动一个http服务
- 该包会绑定了URL:http://localhost或ip:端口/debug/pprof/
- 数据采集和查看
- 概览:http://localhost或ip:端口/debug/pprof/
- 具体的profiles:http://localhost或ip:端口/debug/pprof/类型
其中类型有(打开上面的概览网址即可看到):
- allocs: 内存分配情况的采样信息
- blocks: 阻塞操作情况的采样信息
- cmdline: 显示程序启动命令参数及其参数
- goroutine: 显示当前所有协程的堆栈信息
- heap: 堆上的内存分配情况的采样信息
- mutex: 锁竞争情况的采样信息
- profile: cpu占用情况的采样信息,点击会下载文件
- threadcreate:系统线程创建情况的采样信息
- trace: 程序运行跟踪信息
非持续运行的程序、测试代码这两种场景与服务器程序(上面提到的http引入方式)的不同点如下,其他都相同:
- 非持续运行的程序
- 代码中引入包:runtime/pprof
- 使用的API函数形如:runtime.StartCPUProfile/runtime.StopCPUProfile等
- 具体示例代码可搜索网络或查阅pprof性能调优
- 测试代码: go test -bench . -cpuprofile cpu.prof(其中的点号代表目录,也可以指定特定的函数),其他参数如下(替换cpuprofile的位置):
- benchmem:打印出申请内存的次数
- blockprofile:协程阻塞情况
- memprofile: 协程内存申请信息
- mutexprofile: 互斥情况
- trace:执行调用链情况
不论哪种使用场景,最终都会得到所需的profile文件(比如CPU的、内存的)。而分析就是基于这个文件的,只不过分析的时候交互方式有所区别:
- 网页可视化
- 分析源基于http:
- 以cpu为例,即URL中最后一个词profile:go tool pprof -http=:9000 http://localhost:8000/debug/pprof/profile
- 其他的分析,把URL中的最后一个词替换就行,比如聂村分配情况,可替换成 allocs
- 其他参数:采样时间 -seconds=5,例如 go tool pprof -seconds=5 -http=:9000 http://localhost:8000/debug/pprof/profile
- 数据较详细的文件:curl -o profile.out http://localhost:6060/debug/pprof/profile
- 分析源基于文件:go tool pprof -http=:9000 你的文件
- go 1.8之前,你同时需要可执行二进制文件和数据文件,用go 1.8之后的版本编译的程序,分析时不需要指定二进制文件了
- 分析源基于http:
- 终端交互方式:
- 命令(不需要-http选项,其他都一样,这里以文件为例):go tool pprof cpu.prof
- 输入 web 可以查看到svg图形,其他交互命令,可通过输入 help 获取帮助
分析
整个分析的过程分为两步:
- 导出数据(详情参考本文中的“使用场景”一节)
- 分析数据
- 通过 top 等统计信息初步定位
- 通过可视化精细定位
- 分析函数代码: 当确定出哪个函数耗时之后,可以用pprof分析函数中的哪一行导致的耗时,使用子命令:
list 函数名
pprof的目标是生成可视化的检测报告。报告是根据采集的样本数据从一个跟节点位置开始按调用关系生成层次化的结构。 每个位置包含两个值:
- flat:当前位置自身消耗的值(不包含函数内的调用消耗)
- cum:当前位置及子位置累计的消耗值(即当前函数以及所有调用的函数总消耗)
pprof生成报告的形式有两种:文字形式和可视化图形
文字报告
pprof的文字报告用文字的格式展示了位置的层次结构。文字报告中有5个指标:Flat、Flat%、Sum%、Cum、Cum%
- Flat:函数自身运行耗时
- Flat%:函数自身耗时比例
- Sum%:指的就是每一行的
flat%与上面所有行的flat%总和 - Cum:当前函数加上它所有调用栈的运行总耗时
- Cum%:当前函数加上它所有调用栈的运行总耗时比例
举例说明:函数demo由三部分组成:调用函数foo、自己直接处理一些事情、调用函数bar,其中调用函数foo耗时1秒, 自己直接处理事情耗时3秒,调用函数bar耗时2秒,那么函数demo的flat耗时就是3秒,cum耗时就是6秒。
1
2
3
4
5
func demo() {
foo() // takes 1s
do something directly // takes 3s
bar() // takes 2s
}
可视化图形报告
web页面中经常用到的是 VIEW 菜单系列项:
- Top:同(pprof)中的top命令
- Graph:连线图(展示函数调用线)
- Flame Graph:火焰图
- Peek:同(pprof)中的 text 命令,打印每个调用栈
- Source:同(pprof)中的 list 命令
如果是内存信息,则 菜单 SAMPLE 中有以下介个项:
- alloc_objects:已分配的对象总量(不管是否已释放)
- alloc_space:已分配的内存总量(不管是否已释放)
- inuse_objects: 已分配但尚未释放的对象数量
- inuse_sapce:已分配但尚未释放的内存数量
在图形化的包中包含节点、节点之间的边、字体三个元素。而每个元素又具有颜色和大小两个属性。
- 连线图
- 每个节点的信息包括了包名、函数名、flat、flat%、cum、cum%
- 节点的颜色越红,其cum和cum%越大
- 其颜色越灰白,则cum和cum%越小
- 线条代表了函数的调用链:线条越粗,代表指向的函数消耗了越多的资源
- 线条的样式代表了调用关系:实线代表直接调用;虚线代表中间少了几个节点
- 火焰图:可以将程序的 函数调用堆栈关系和资源占比 两个信息可视化,常用用来做程序的CPU和内存的分析。
- 可以分析函数执行的频繁程度
- 可以分析哪些函数经常阻塞(profie分析)
- 可以分析哪些函数频繁分配内存(heap分析)
- 火焰图两个作用:
- 可视化函数调用链关系
- 可视化资源占比:跨度越大,占比资源(CPU/内存)越大
- 火焰图解读:
- 火焰图的横向长度表示cum,相比下面超出的一截代表flat
- 火焰图可以进行点击,细化调用关系,一层层查看更具体的细节
- y 轴表示调用栈:每一层都是一个函数。调用栈越深,火焰就越高
- x 轴表示抽样数:如果一个函数在 x 轴占据的宽度越宽,就表示它被抽到的次数多,即执行的时间长
- 只要有”平顶”(plateaus,即该函数占据宽度独大,没有进一步细化),就表示该函数可能存在性能问题
- 火焰图互动:
- 鼠标悬浮:火焰的每一层都会标注函数名,鼠标悬浮时会显示完整的函数名、抽样抽中的次数、占据总抽样次数的百分比
- 点击放大:
- 在某一层点击,火焰图会水平放大,该层会占据所有宽度,显示详细信息
- 点击上一层会回到上一层调用关系,点击root则会回到最上层
- 搜索:按下 Ctrl + F 会显示一个搜索框,用户可以输入关键词或正则表达式,所有符合条件的函数名会高亮显示。

其他类似工具
- 基准测试
- promethus
- 算法时间复杂度分析大 O表示法
- 适配操作系统存储层次和缓存策略
- 使用dlv分析golang进程cpu占用高问题
- go程序cpu过高问题排查方法
- Go 中的性能分析和执行跟踪
trace
你是否遇到过:为什么在程序中增加了并发,但并没有给它带来更好的性能?go执行跟踪程序可以帮助回答这些疑问,还有其他和其有关性能的问题,例如延迟、竞争和较低的并行效率。 在真实的程序中还包含许多的隐藏动作,例如:
- Goroutine 在执行时会做哪些操作?
- Goroutine 执行/阻塞了多长时间?
- Syscall 在什么时候被阻止?在哪里被阻止的?
- 谁又锁/解锁了 Goroutine ?
- GC 是怎么影响到 Goroutine 的执行的?
在引入执行trace程序之前,已经有了pprof内存和CPU分析器,那么为什么它还会被添加到官方的工具链中呢?虽然CPU分析器做了一件很好的工作, 告诉你什么函数占用了最多的CPU时间,但它并不能帮助你确定是什么阻止了goroutine运行,或者在可用的OS线程上如何调度goroutines。 这正是跟踪器真正起作用的地方。trace设计文档很好地解释了跟踪程序背后的动机以及它是如何被设计和工作的。
引入trace
分析trace之前需要先得到trace数据文件,才能做进一步分析:
- 代码中引入trace
- 可终止的程序中引入方式:
- 在程序中引入包 runtime/trace,程序退出时会把trace信息输出到控制台
- 执行命令导出trace数据文件:go run main.go 2> trace.out
- 服务器程序引入方式:
- 想要从一个运行的web应用收集trace, 你需要添加 /debug/pprof/trace handler。下面的代码示例展示了如何通过简单地导入 net/http/pprof 包为 http.DefaultServerMux 做到这一点。
- curl localhost:8181/debug/pprof/trace?seconds=10 > trace.out
- 可终止的程序中引入方式:
- 启动可视化界面:go tool trace trace.out
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
// 可终止的程序引入方式
package main
import (
"os"
"runtime/trace"
)
func main() {
trace.Start(os.Stderr)
defer trace.Stop()
// create new channel of type int
ch := make(chan int)
// start new anonymous goroutine
go func() {
// send 42 to channel
ch <- 42
}()
// read from channel
<-ch
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
// 服务器程序引入方式:
package main
import (
"net/http"
_
"net/http/pprof"
)
func main() {
http.Handle("/hello", http.HandlerFunc(helloHandler))
http.ListenAndServe("localhost:8181", http.DefaultServeMux)
}
func helloHandler(w http.ResponseWriter, r *http.Request) {
w.Write([]byte("hello world!"))
}
可视化界面解读
启动可视化界面之后,会出现以下项目:
- View trace:最复杂、最强大和交互式的可视化显示了整个程序执行的时间轴。 这个视图显示了在每个虚拟处理器上运行着什么,以及什么是被阻塞等待运行的。稍后我们将在这篇文章中深入探讨这个视图。注意它只能在chrome上显示。
- Goroutine analysis:显示了在整个执行过程中,每种类型的goroutines是如何创建的。在选择一种类型之后就可以看到关于这种类型的goroutine的信息。 例如,在试图从mutex获取锁、从网络读取、运行等等每个goroutine被阻塞的时间。
- Network/Sync/Syscall blocking profile:这些图表显示了goroutines在这些资源上所花费的时间。它们非常接近pprof上的内存/cpu分析。这是分析锁竞争的最佳选择。
- Scheduler latency profiler:为调度器级别的信息提供计时功能,显示调度在哪里最耗费时间。
在刚开始查看问题时,除非是很明显的现象,否则不应该一开始就陷入细节。界面分析步骤:
- 先查看 Scheduler latency profile 了解一些概览信息
- 看 “Goroutine analysis”:
- 我们能通过这个功能看到整个运行过程中,每个函数块有多少个有 Goroutine 在跑
- 观察每个的 Goroutine 的运行开销都花费在哪个阶段
- 每个 Goroutine 具体做了些什么事情,可通过点击具体细项去观察
- 这块能够很好的帮助我们对 Goroutine 运行阶段做一个的剖析,可以得知到底慢哪,然后再决定下一步的排查方向
- 查看 “View trace”:
- 在对当前程序的 Goroutine 运行分布有了初步了解后,我们再通过 “查看跟踪” 看看之间的关联性
- 具体细节可参考文章
- 查出问题之后可以:
- 修复问题前后比较 trace 数据和可视化情况
- 把问题抽象成 demo,再用 trace 工具突出分析
如果加强 trace 分析经验,可以:
- 经常使用 trace:尽量把服务器程序本地化。
- 即不依赖任何外部动态数据或组件,在本地就可以正常运行起来,并制造输入来像跑在服务器一样执行所有业务逻辑(包括外部依赖的mock)。
- 尽量不影响线上或测试环境正常运作的情况下,实现trace分析自由(具体实施方法可参考”业务测试”一节)
- 制造bug或demo程序,练习或观察trace表现。
- 网络收集分析案例或者整理自己遇到过的案例
常见优化
优化GC
垃圾回收(Garbage Collection,简称 GC)是一种内存管理策略,由垃圾收集器以类似守护协程的方式在后台运作,按照既定的策略为用户回收那些不再被使用的对象,释放对应的内存空间.
- 优势:
- 屏蔽内存分配和释放的细节,开发人员能更好地聚焦业务逻辑实现
- 手动内存分配在大项目协作时,需要具备指针全局跟踪的视野,很容易出现内存污染或悬空指针等内存问题,导致内存bug剧增。
- 劣势:
- 内存自动分配自动回收,但开发人员也失去了自行分配内存的自由:将释放内存的工作委托给垃圾回收模块,研发人员得到了减负, 但同时也失去了控制主权. 除了运用有限的GC调优参数外,更多的自由度都被阉割,需要向系统看齐,服从设定.
- 增加了额外成本:全局的垃圾回收模块化零为整,会需要额外的状态信息用以存储全局的内存使用情况. 且部分时间需要中断整个程序用以支持垃圾回收工作的执行,这些都是GC额外产生的成本.
GC 在并发度复杂度高且性能不要求极致的项目中,能很好的提高开发效率。但在性能追求极致的项目中,GC可能会成为性能瓶颈。
传统的GC算法
GC 一般分为两个大的阶段,不同的 GC 算法只不过是在这两个阶段的实现上采取了不同的策略,同时为了弥补该策略带来的副作用而做了一些优化策略。
- 标记:识别存活对象和垃圾对象
- 清扫:回收垃圾对象
以下通过表格的形式展示常用传统GC算法。 | 算法 | 特点 | 备注 | | —- | —- | —- | | 标记清除 | 标记存活对象,清扫未标记对象 | 默认是垃圾对象,不做空间压缩或重新编排 | | 标记压缩 | 同标记清除,但清扫时会做空间压缩或重新编排 | 可减少内存碎片,但复杂度高,有性能开销 | | 半空间复制 | 每轮GC只使用空间的一般,GC 时会把存活对象转移到另一半 | 空间换时间,降低了复杂度,但浪费了一半空间 | | 引用计数 | 对象每被引用一次加1,每被删除引用一次减1,为0则被视为垃圾对象 | 很难解决循环引用和自引用问题 |
Go GC 算法
Go GC 算法有一个较长的进化过程,我们首先从较新的算法开始介绍,然后再简述其历史。目前 Go GC 算法大方向已经确定:
- 三色标记法
- 混合写屏障机制
- GC 和用户协程最大化并发进行
Golang采用 TCMalloc 机制,依据对象的大小将其归属为到事先划分好的spanClass当中,这样能够消解外部碎片的问题,将问题限制在相对可控的内部碎片当中
三色标记法
对于实时系统而言,垃圾回收系统可能是一个极大的隐患,因为在垃圾回收的时候需要将整个应用程序暂停。 所以在我们设计消息总线系统的时候,需要小心地选择我们的语言。 Go一直在强调它的低延迟,但是它真的做到了吗?如果是的,它是怎么做到的呢?
把所有对象分为三类:白色、灰色、黑色。其定义如下:
| 对象 | 特点 | 备注 |
|---|---|---|
| 白色对象 | GC 标记前默认的对象标记,GC 标记完成后则为垃圾对象 | 所有对象假设默认都不可达,标记完成后,不可达才视为真的不可达 |
| 灰色对象 | 已被访问,但其直接引用的对象还未扫描完成,即至少还有一个直接引用对象未被扫描 | 表示该对象的直接引用对象还在扫描中 |
| 黑色对象 | 该对象及其直接引用的所有对象都已被访问或标记过 | 表示已确定为可达对象(一旦灰色对象全部转为黑色,则表示标记阶段完成) |
需要指出的是,黑色对象需要包括:
- 不存在引用外部指针的对象
- 从 root 区域出发扫描到的对象:root 区域主要是程序运行到当前时刻的栈和全局数据区域。
从定义中可以得到以下推论:
- 黑色对象直接引用的所有对象,要么是黑色,要么是灰色,不可能是白色(否则意味着漏标,将被错误回收,导致致命错误)。这是三色标记算法正确性保障的前提条件。
- 所有灰色对象在GC标记结束后都会变成黑色对象
- 灰色对象可以认为是波面,该波面由白色传导到黑色,未被传导的则认为不可达,即为垃圾对象。
三色标记过程与用户业务执行过程是并发的,可能需要考虑以下问题:
- 已被标记为黑色的对象,在三色标记过程中被用户解除引用,造成错标。这个错误会在下一轮GC中得到纠正。可见,这只会延后垃圾对象的回收,对用户程序逻辑无影响。
- 由于起初默认是白色对象,当某个对象已经被标记为黑色对象(即改对象及其直接子对象已经标记完成)。此时用户新建了一个对象(默认为白色对象), 并且该对象是被黑色对象引用的,GC认为该白色对象已标记完成,会错误地把该白色对象认为是垃圾对象,即发生了漏标现象。
想要在标记过程中保证安全性,不漏标,我们需要达成以下两种三色不变式(Tri-color invariant)中的任意一种:
- 强三色不变式:黑色对象不能指向白色对象,只能指向灰色或黑色对象;
- 弱三色不变式:黑色对象指向的白色对象,必须包含一条从灰色对象经由多个白色对象的可达路径。
如何解决上面的漏标问题?满足三色不变式,一般可以考虑以下几种方式:
- 读写屏障(有多种变形):在读写操作前后插入一段代码,用于记录一些信息、保存某些数据等,概念类似于AOP。
- 插入写屏障:实现强三色不变式,保证当一个黑色对象指向一个白色对象前,会先触发屏障将白色对象置为灰色,再建立引用。
- 删除写屏障:实现弱三色不变式,保证当一个白色对象即将被上游删除引用前,会触发屏障将其置灰,之后再删除上游指向其的引用。
- 混合写屏障:混合使用了插入写屏障和删除写屏障技术,为了减少对栈上对象的重复扫描(栈对象扫描需要STW)。
- GC开始将栈上的对象全部扫描并标记为黑色(之后不再进行第二次重复扫描,无需STW)
- GC期间,任何在栈上创建的新对象,都标记为黑色
- 被删除的对象标记为灰色
- 被添加的对象标记为灰色
- 增量更新:通过写屏障记录GC标记过程中用户解除引用或新建对象产生的白色对象,等到垃圾清理时,STW (stop the world,指在进行垃圾回收时,会暂停应用程序的运行,以便进行垃圾回收操作。这意味着在进行垃圾回收时,应用程序将无法继续执行)对被记录下的对象再扫描一次。
- 原始快照:GC 扫描期间直接把新建对象标记为黑色
如果一个并行 GC 收集器在处理超大内存堆时能够达到极低的延迟,那么为什么还有人在用 stop-the-world 的 GC 收集器呢?难道 Go 的 GC 收集器还不够优秀吗? 这不是绝对的,因为低延迟是有开销的。最主要的开销就是,低延迟削减了吞吐量。并发需要额外的同步和赋值操作,而这些操作将会占用程序的处理逻辑的时间。 而 Haskell 的 GHC 则针对吞吐量进行了优化,Go 则专注于延迟,我们在考虑采用哪种语言的时候需要针对我们自己的需求进行选择, 对于推送系统这种实时性要求比较高的系统,选择Go语言则是权衡之下得到的选择。
GC过程
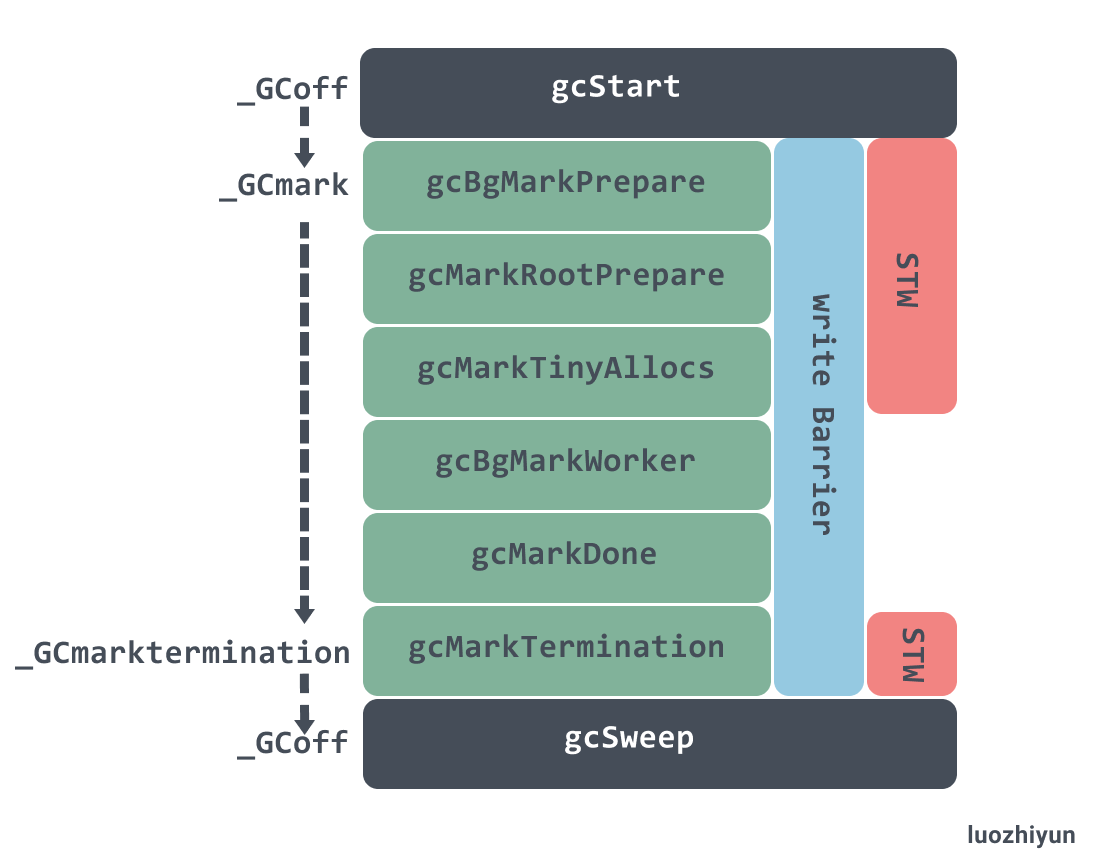
GC 相关的代码在runtime/mgc.go文件下。通过注释介绍我们可以知道 GC 一共分为4个阶段。除了走读代码了解GC过程之外,还可以借助pprof的可视化跟踪过程。
- sweep termination(清理终止)
- 会触发 STW ,所有的 P(处理器) 都会进入 safe-point(安全点);
- 清理未被清理的 span(一组连续的Page被称为Span,而page指的是按页分配)
- the mark phase(标记阶段)
- 将 _GCoff GC 状态 改成 _GCmark,开启 Write Barrier (写入屏障)、mutator assists(协助线程),将根对象入队;
- 恢复程序执行,mark workers(标记进程)和 mutator assists(协助线程)会开始并发标记内存中的对象。对于任何指针写入和新的指针值,都会被写屏障覆盖,而所有新创建的对象都会被直接标记成黑色;
- GC 执行根节点的标记,这包括扫描所有的栈、全局对象以及不在堆中的运行时数据结构。扫描goroutine 栈绘导致 goroutine 停止,并对栈上找到的所有指针加置灰,然后继续执行 goroutine。
- GC 在遍历灰色对象队列的时候,会将灰色对象变成黑色,并将该对象指向的对象置灰;
- GC 会使用分布式终止算法(distributed termination algorithm)来检测何时不再有根标记作业或灰色对象,如果没有了 GC 会转为mark termination(标记终止)
- mark termination(标记终止)
- STW,然后将 GC 阶段转为 _GCmarktermination,关闭 GC 工作线程以及 mutator assists(协助线程);
- 执行清理,如 flush mcache
- he sweep phase(清理阶段)
- 将 GC 状态转变至 _GCoff,初始化清理状态并关闭 Write Barrier(写入屏障);
- 恢复程序执行,从此开始新创建的对象都是白色的;
- 后台并发清理所有的内存管理单元
GC 标记的工作是分配 25% 的 CPU 来进行 GC 操作,所以有可能 GC 的标记工作线程比应用程序的分配内存慢, 导致永远标记不完,那么这个时候就需要应用程序的线程来协助完成标记工作。
下面这张图显示了 gcStart 过程中状态变化,以及 STW 停顿的方法,写屏障启用的周期:
GC优化
了解了GC的触发时机和频率之后,才能对GC进行更好的优化。
- 主动触发:runtime.GC()强制触发GC
- 申请内存时触发:Go 语言运行时的默认配置会在堆内存达到上一次垃圾收集的 2 倍时,触发新一轮的垃圾回收,这个行为可以通过 GOGC 变量调整。它的默认值为 100,即增长 100% 的堆内存才会触发 GC。 再分配内存时,判断当前内存是否达到阈值会触发新一轮GC(比如当前为 4MB,GOGC=100,4MB + 4MB * GOGC / 100)
- 系统定时触发:上次GC间隔达到了runtime.forcegcperiod(默认2分钟),会启动GC
调优方法和总体思路(做减法,不做多余的事情):
- 合理化内存分配速度
- 内存池化,降低并复用已经申请的内存
- 减少对象数量,合理优化数据结构
- 减少内存使用总量
- 减少内存分配动态分配频度
- 尽可能在栈上分配内存
- 合理使用空结构体(空结构体不占用内存空间)
- 调整GOGC:事实上,这个值很难确定,可以采用手段GO 内存 ballast。 ballast 的大小可以参考使用该手段之前的虚拟内存和物理内存,预估一个值。另外,可参考文章聊聊两个Go即将过时的GC优化策略
GC 作为内存垃圾回收的组件,在检测和执行回收时会占用CPU资源,同时可能会引起业务时延的突然飙升。因此有时在以下两方面进行优化是值得的:
- GC 检测和标记
- GC 执行垃圾回收
减少垃圾回收所用的协程数
在Go的运行模型GMP中,每个P会运行一个gcBgMarkWorker用于垃圾回收。 是否由于P的数量不正确导致GC过多,从而CPU使用率过高? Go程序在运行时,会使用查询到的CPU的数量作为默认的P的数量,简单地用一个Go脚本验证一下:
1
2
3
4
5
func main() {
cpu := runtime.NumCPU()
procs := runtime.GOMAXPROCS(0)
fmt.Println("cpu num:", cpu, " GOMAXPROCS:", procs)
}
对于容器或云主机而言,可能会出现:在程序运行时读取到的CPU的数量是宿主机的CPU数量,而不是容器设置的CPU核心数量。 通过环境变量GOMAXPROCS可以设置Go运行时P的数量。
由于Go程序本身的特性,在运行时会默认读取系统的CPU核心数作为最大的并行执行线程数。 而在容器内,读取到的是宿主机的CPU核心数。 在容器被分配的CPU核心数远小于宿主机的CPU核心数的情况下, 就会发生CPU使用率异常升高的情况。 出现问题的这个服务,其业务特点就是周期性的峰值QPS极高, 所以会较为明显地观察出CPU使用率异常的现象。 通过配置环境变量 GOMAXPROCS,指定最大的并行执行线程数,可以解决CPU使用率异常的问题。 由于业务逻辑的不同,达到最佳性能的GOMAXPROCS也不同。 《The Way to Go》曾给出过一个经验公式:GOMAXPROCS=CPU数量-1。 在容器中,通常设置成申请的核心数即可。 另外,Uber开源了一个自动调整GOMAXPROCS的库:https://github.com/uber-go/automaxprocs。 具体细节参考.net runtime占用cpu_Go服务在容器内CPU使用率异常问题排查手记。
减少标记阶段扫描耗时
降低标记阶段的耗时,需要深刻了解golang语言垃圾回收的理论和代码实现机制。一般从以下方面入手:
- 减少申请内存的次数(比如可在用户层重用内存,减少申请次数)
- 减少申请内存的对象个数(即使申请的内存大小一样,但作为一个整体使用与分割成多块来使用,效果不一样)
- 减少申请内存的频度(即使在相同时间内申请的次数相同,但时间上的分布不同,效果也不同)
- 减少GC标记扫描的次数或频度
权衡使用指针还是内存拷贝,尽量减少指针的使用,至于优化措施是否过时(GC算法在不断优化中), 需要借助”GC分析工具“进行验证。
优化的本质:尽最大努力不做多余的事情。如何做到这一点:
- 对业务逻辑充分理解,去掉多余的逻辑,减少代码堆砌;
- 对编程语言底层原理有充分的理解,使用更高效的方式实现相同的效果。
- 使用高效的数据结构,简化逻辑的复杂性
GC分析工具
GC的分析工具有:
- go tool pprof:CPU和内存分析
- go tool trace
- go bulid -gcflags = “-m”:逃逸分析
- GODEBUG=”gctrace=1”:跟踪GC行为
- 最常用的是GODEBUG=”gctrace=1”,下图中展示的是采用GODEBUG=”gctrace=1”分析GC的情况

用pprof中的cpu profile时,可以使用 top cum命令或直接对这些函数使用list命令,并将注意力集中在累计百分比列上。
- runtime.gcBgMarkWorker:专用标记工作goroutine的入口点。这里花费的时间与GC频率以及对象图的复杂性和大小成比例。它表示应用程序标记和扫描所用时间的基准。 注意:在一个大部分时间都处于空闲状态的Go应用程序中,Go GC会消耗额外的(空闲的)CPU资源来更快地完成任务。
- runtime.mallocgc:堆内存的内存分配器的入口点。此处花费的大量累积时间(> 15%)通常表示分配了大量内存。
- runtime.gcAssistAlloc:goroutine进入这个函数是为了腾出一些时间来帮助GC进行扫描和标记。 这里花费的大量累积时间(> 5%)表明应用程序在分配速度方面可能超过了GC。它表示GC的影响程度特别高,并且还表示应用程序在标记和扫描上花费的时间。 请注意,它包含在runtime.mallocgc调用树中,因此它也会使该调用树累计时间增加。
在确定GC是一个巨大开销的来源之后,消除堆分配的下一步是找出它们中的大多数来自哪里。 为此,内存profile文件(实际上是堆内存profile文件)非常有用。
内存profile文件描述了程序堆中分配的来源,并通过分配时的堆栈跟踪来标识它们。每个内存profile文件可以按四种方式分析:
- inuse_objects:活动对象的数量
- inuse_space:按活动对象使用的内存量(以字节为单位)
- alloc_objects:自Go程序开始执行以来已经分配的对象数
- alloc_space:自Go程序开始执行以来所分配的内存总量
在这些不同的堆内存视图之间切换可以通过pprof工具的-sample_index标志来完成,或者在交互式使用该工具时通过sample_index选项来完成。
为了降低GC成本,alloc_space通常是最有用的视图,因为它直接对应于分配率。此视图将指示可提供最大益处的分配热点。
GC源码导读
原理需要被源码论证。go GC 经过了几个大版本的进化,如果需要知晓其优化思路与过程,可以先读最新版的源码,然后再从最老的版本读至最新版。 在读历史各个版本时,需要关注其不同点或优化点,并始终抱着以下这些问题进行:
- 为什么需要这些优化
- 这些优化会引入什么新的问题
- 该优化在哪些场景有很好的效果
- 该优化在哪些场景却会带来更差的效果
- 还可以怎样进一步优化
- 用户基于这些优化,用户可以怎么做,从中能得到更大的好处。
GC 演化简史:
- 在Go1.3及之前使用的是标记清除法,其中标记清除也经历了串行处理和并行处理阶段;
- 在Go1.5实现了三色标记法,大幅的降低了STW的时间;
- 在Go1.7实现了并行的清理垃圾过程,将垃圾收集的时间大幅降低。
- 在Go1.8引入了混合写屏障,大幅的降低了标记的时间。
- 在后续的版本中基于以上算法,优化了内存分配、标记开始结束等继续对GC做了部分优化
源码文件位置
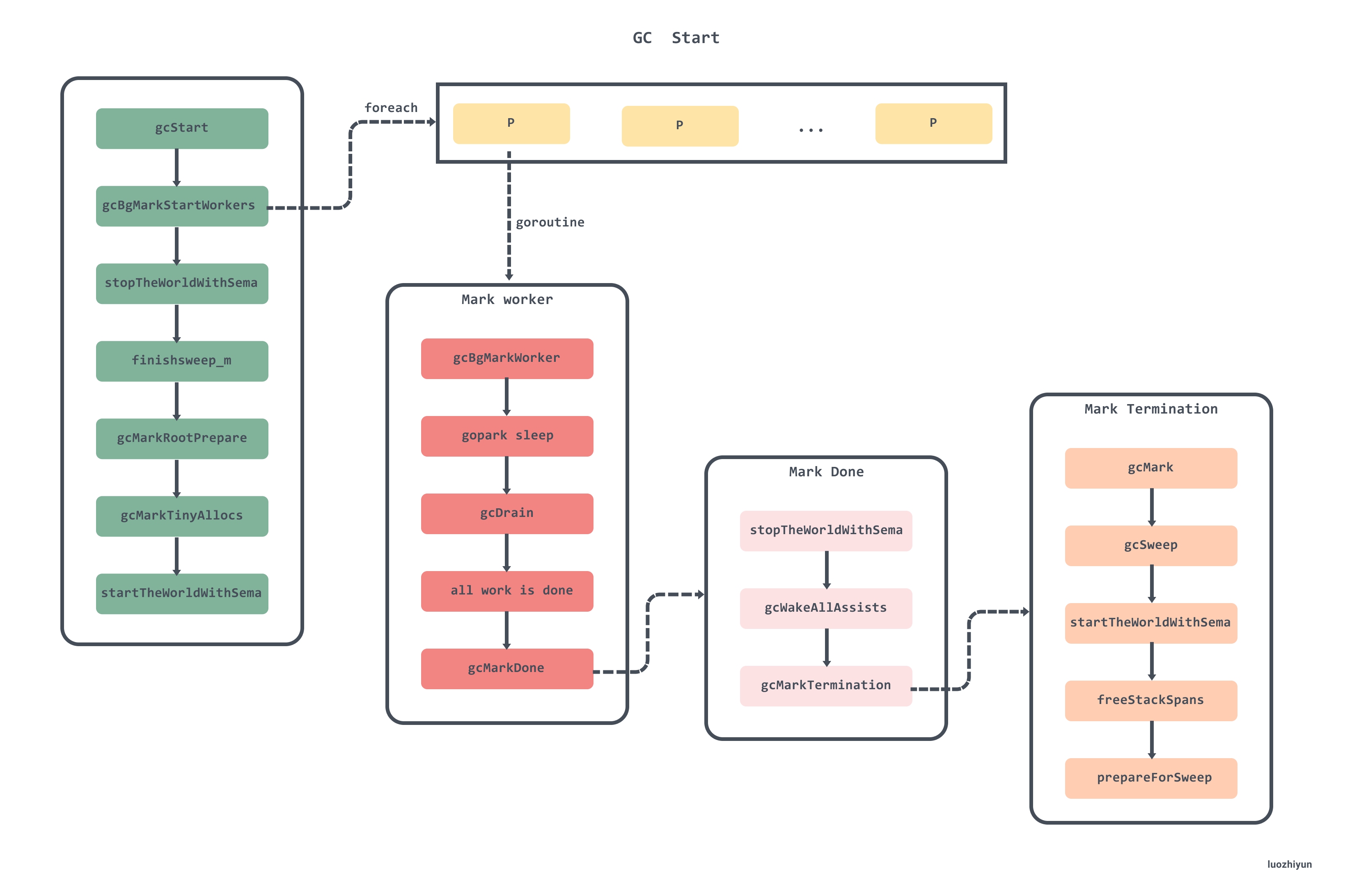
| 环节 | 文件位置 |
|---|---|
| 主干流程 | runtime/mgc.go |
| 调步策略 | runtime/mgcspacer.go |
| 并发标记 | runtime/mgcmark.go |
| 清扫流程 | runtime/msweep.go |
触发GC链路
- 定时触发GC
| 方法 | 文件 |
|---|---|
| init | runtime/proc.go |
| forcegchelper | runtime/proc.go |
| main | runtime/proc.go |
| sysmon | runtime/proc.go |
| injectglist | runtime/proc.go |
| gcStart | runtime/mgc.go |
| gcTrigger.test | runtime/mgc.go |
- 对象分配触发
| 方法 | 文件 |
|---|---|
| mallocgc | runtime/malloc.go |
| gcTrigger.test | runtime/mgc.go |
| gcStart | runtime/mgc.go |
标记准备
| 方法 | 文件 |
|---|---|
| gcStart | runtime/mgc.go |
| gcBgMarkStartWorkers | runtime/mgc.go |
| gcBgMarkWorker | runtime/mgc.go |
| stopTheWorldWithSema | runtime/mgc.go |
| gcControllerState.startCycle | runtime/mgcspacer.go |
| setGCPhase | runtime/mgc.go |
| gcMarkRootPrepare | runtime/mgc.go |
| gcMarkTinyAllocs | runtime/mgc.go |
| startTheWorldWithSema | runtime/mgc.go |
并发标记
- 调度标记协程
| 方法 | 文件 |
| schedule | runtime/proc.go |
| findRunnable | runtime/proc.go |
| gcControllerState.findRunnableGCWorker | runtime/mgcspacer.go |
| execute | runtime/proc.go |
- 并发标记
| 方法 | 文件 |
| gcBgMarkWorker | runtime/mgc.go |
| gcDrain | runtime/mgcmark.go |
| markroot | runtime/mgcmark.go |
| scanobject | runtime/mgcmark.go |
| greyobject | runtime/mgcmark.go |
| markBits.setMarked | runtime/mbitmap.go |
| gcWork.putFast/put | runtime/mgcwork.go |
标记清扫
| 方法 | 文件 |
| gcBgMarkWorker | runtime/mgc.go |
| gcMarkDone | runtime/mgc.go |
| stopTheWorldWithSema | runtime/proc.go |
| gcMarkTermination | runtime/mgc.go |
| gcSweep | runtime/mgc.go |
| sweepone | runtime/mgcsweep.go |
| sweepLocked.sweep | runtime/mgcsweep.go |
| startTheWorldWithSema | runtime/proc.go |
逃逸分析
所谓逃逸分析(Escape analysis)是指由编译器决定内存分配的位置,不需要程序员指定。 函数中申请一个新的对象
如果分配在栈中,则函数执行结束可自动将内存回收; 如果分配在堆中,则函数执行结束可交给GC(垃圾回收)处理; 有了逃逸分析,返回函数局部变量将变得可能,除此之外,逃逸分析还跟闭包息息相关,了解哪些场景下对象会逃逸至关重要。
逃逸策略
每当函数中申请新的对象,编译器会跟据该对象是否被函数外部引用来决定是否逃逸:
- 如果函数外部没有引用,则优先放到栈中; 注意,对于函数外部没有引用的对象,也有可能放到堆中,比如内存过大超过栈的存储能力
- 如果函数外部存在引用,则必定放到堆中;
逃逸场景
通过编译参数-gcflag=-m可以查年编译过程中的逃逸分析:
指针逃逸:返回局部变量的指针,这其实是一个典型的变量逃逸案例。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
package main
type Student struct {
Name string
Age int
}
func StudentRegister(name string, age int) *Student {
s := new(Student) //局部变量s逃逸到堆
s.Name = name
s.Age = age
return s
}
func main() {
StudentRegister("Jim", 18)
}
函数StudentRegister()内部s为局部变量,其值通过函数返回值返回, s本身为一指针,其指向的内存地址不会是栈而是堆,这就是典型的逃逸案例。
通过编译参数-gcflag=-m可以查年编译过程中的逃逸分析:
1
2
3
4
5
6
7
8
D:\SourceCode\GoExpert\src>go build -gcflags=-m
# _/D_/SourceCode/GoExpert/src
.\main.go:8: can inline StudentRegister
.\main.go:17: can inline main
.\main.go:18: inlining call to StudentRegister
.\main.go:8: leaking param: name
.\main.go:9: new(Student) escapes to heap
.\main.go:18: main new(Student) does not escape
可见在StudentRegister()函数中,也即代码第9行显示”escapes to heap”, 代表该行内存分配发生了逃逸现象。
栈空间不足逃逸
比如以下代码是否存在逃逸,与所需内存空间有关。可通过修改make参数和 执行go build -gcflags=-m进行探究。
1
2
3
4
5
6
7
8
9
10
11
12
13
package main
func Slice() {
s := make([]int, 1000, 1000)
for index, _ := range s {
s[index] = index
}
}
func main() {
Slice()
}
实际上当栈空间不足以存放当前对象时或无法判断当前切片长度时会将对象分配到堆中。
动态类型逃逸
很多函数参数为interface类型,比如fmt.Println(a …interface{}), 编译期间很难确定其参数的具体类型,也会产生逃逸。
闭包引用逃逸
某著名的开源框架实现了某个返回Fibonacci数列的函数:
1
2
3
4
5
6
7
func Fibonacci() func() int {
a, b := 0, 1
return func() int {
a, b = b, a+b
return a
}
}
该函数返回一个闭包,闭包引用了函数的局部变量a和b,使用时通过该函数获取该闭包, 然后每次执行闭包都会依次输出Fibonacci数列。 完整的示例程序如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
package main
import "fmt"
func Fibonacci() func() int {
a, b := 0, 1
return func() int {
a, b = b, a+b
return a
}
}
func main() {
f := Fibonacci()
for i := 0; i < 10; i++ {
fmt.Printf("Fibonacci: %d\n", f())
}
}
Fibonacci()函数中原本属于局部变量的a和b由于闭包的引用,不得不将二者放到堆上,以致产生逃逸。
指针必然不逃逸的情况
- 指针被未发生逃逸的变量引用
- 仅仅在函数内对变量做取址操作,未将指针传出
逃逸总结
- 栈上分配的对象比在堆中分配的有更高的效率
- 栈上分配的内存不需要GC处理
- 堆上分配的内存使用完毕后会交给GC处理
- 逃逸分析目的是决定内存分配地址是栈还是堆
- 逃逸分析在编译阶段完成
思考一下这个问题:函数传递指针真的比传值效率高吗? 我们知道传递指针可以减少底层值的拷贝,可以提高效率,但是如果拷贝的数据量小, 由于指针传递会产生逃逸,可能会使用堆,也可能会增加GC的负担,所以传递指针不一定是高效的。
其他优化
- Go 性能:你知道的越多,不知道的也就越多
- Go性能优化及实践
- Go 语言中各式各样的优化手段
- go 性能优化
- GO项目性能优化大赏
[郑建勋:Go程序性能分层优化 CPU篇](https://zhuanlan.zhihu.com/p/516942933?utm_id=0)
性能诊断
- golang性能诊断看这篇就够了
- 通过 profiling 定位 golang 性能问题 - 内存篇
- 使用dlv分析golang进程cpu占用高问题
- Go 性能调优之 —— 基准测试
- Go 云端程序的持续分析
- 优化你的go代码的几个工具
- 译文 Go 高性能系列教程之二:性能评估和分析
- Go 程序性能分析
- Go程序的问题诊断和性能调优指南
- GO的花式调优技术
- golang-性能分析(原生工具)
- go程序cpu过高问题排查方法
- 高cpu进程排查方法
- 7种 Go 程序性能分析方法
- golang性能分析之trace
- golang性能诊断看这篇就够了
- Go程序性能分析方法(一文全解)
- go 静态检查工具
优化定时器
类型或数据结构优化
- Go 泛型使用与性能对比
- 详解简单高效的Go struct优化
- map内存优化
- defer滥用
- 闭包慎用
- chan的适用场景
- interface滥用
- 不得不用refect时的优化手段
- chan回收
- Go语言性能优化- For Range 性能研究
cgo或跨语言调用优化
低级优化
综合优化
- Go 高性能编程技法
- GO高性能编程精华
- golang性能优化实践
- go语言最全优化技巧总结,值得收藏!
- 高德Go生态的服务稳定性建设|性能优化的实战总结
- Go 性能调优之 —— 技巧
- Go 性能调优之 —— 总结
- Golang号称高并发,但高并发时性能不高解决办法
- Golang性能优化技巧(三)
- go 使用中的一些优化建议和技巧,第一篇『基础结构优化』
- 性能优化实战:百万级WebSockets和Go语言
- 优化 Golang 分布式行情推送的性能瓶颈
- 批处理
- 大规模Go项目几乎必踏的几个坑 - Dragonboat为例
- go 语言实践-goroutine+chan 并不是 CSP 的最佳方式
- Go语言的自动内存管理及优化(字节跳动Balanced GC优化方案)(Day5)
- 最接地气的go服务优化指南
原理篇
只有理解原理,才能:
- 养成高性能且可读性强的代码习惯
- 理解性能工具的指标表征
- 定位性能问题
- 提出较为准确和彻底的优化方案
参考文档
- 深入golang runtime的调度
- 深入理解Go语言与并发编程底层原理
- Golang底层原理剖析之闭包
- Golang中闭包的实现原理
- Golang原理分析:闭包及for range延迟绑定问题原理及解决
- Go语言Channel的底层原理详解
- Go 内存对齐没有秘密
- 深入理解 Go 语言的垃圾回收
- Golang 垃圾回收原理分析
- Go 垃圾回收原理
- Go 的垃圾回收机制在实践中有哪些需要注意的地方?
- Go的垃圾回收(GC),详细总结
- Go的垃圾回收机制
- 深入Go:垃圾回收的演进
- Go 垃圾回收(四)——一次完整的回收
- 揭秘golang垃圾回收!三色标记法深入剖析
- 揭秘golang垃圾回收!三色标记法深入剖析
- Go语言实时GC - 三色标记算法
- 两万字长文带你深入Go语言GC源码
- 可视化Go内存管理
- Go 垃圾回收器指南
- Golang底层原理剖析之闭包
- go select编译期的优化处理逻辑使用场景分析
- Golang底层原理剖析专栏汇总
- Golang源码探究 —— chan
- 图文并茂:彻底理解Go中Chan底层同步原理
- 大厂后台开发基本功修炼路线和经典资料
- go-内存管理篇(二) 万字总结-golang内存分配篇
- 一篇文章讲清Go的内存布局和分配原理
- Golang实现带优先级的channel